SeAT - ❓-support - Page 2
[LBS-C]Thess/Jarvande/Panymaris
7 May 2024 04:22
An issue just doesn't fix itself, but glad I helped. I was looking through someone's PHP code trying to understand your issue for the fun. 🙂
Joseph Null
7 May 2024 11:04
what should i do to update? Since my seat5 now have some problem that cannot decrease the esi
esi refresh frequence
which one in "Schedule" can be decrease to decrease the stress of server
Crypta Electrica
7 May 2024 19:21
The bulk of the fetching is scheduled by the buckets update command. This was the same on v4.
Default is every 2m. As there is 30 buckets, this means the update rate is hourly per character by default
Nyzio
8 May 2024 13:07
hello all, if I changed something in the .env file what am I supposed to do to get seat to read the updated file?
in my case I added a redis password but it's not connecting properly :(
Capt Maniac
8 May 2024 13:56
If docker you can down and up -d your instance.
Nyzio
8 May 2024 13:57
I am bare metal sadly
update seat wasn't the issue I pepegad the redis conf
on another note my seat install is still consistently failing jobs, and by logs it's always market history
Capt Maniac
8 May 2024 17:42
In bare metal stoping and starting the services should do it, I believe.
How many failed jobs? There will always be failed jobs from what I have seen.
Joseph Null
8 May 2024 23:46
I still remember there is a bug that if we change the Schedule, it will reset when reboot. Does it fixed already? How can I get the update?
Crypta Electrica
9 May 2024 00:02
That was a feature at the time, not a bug. But did happen. That was also removed a while ago. The update process is the same as any other update.
SneaktSquid
9 May 2024 10:03
Hello there! Anyone here running SeAT on unraid? I am having issues getting it up and running
Crypta Electrica
9 May 2024 10:14
https://dontasktoask.com/
Suggest you read that one 🙂
SneaktSquid
9 May 2024 10:16
Ah well sorry about that, just had the reverse happen many times on various discords when I ask about unraid that "this is not unraid support"
My problem is that the SeAT containers are saying the database might be sleeping, even though the mariadb container is on the same network as seat, seems like they don't want to connect
Any suggestions? Getting a "Database might not be ready yet" message in the logs for the SeAT containers
Crypta Electrica
9 May 2024 10:30
That typically would indicate that the containers are unable to communicate..
You say the same network, but in unraid I dont recall you can set the docker network, only the network type. So you may neet to change your environment variables to point to the IP instead of the container name
SneaktSquid
9 May 2024 11:06
I have the db_host variable set to the ip of my mariadb
Crypta Electrica
9 May 2024 11:07
Can you confirm that mariadb is accessible at that ip from somewhere else on the network? Also what do the logs for the mariadb container show?
SneaktSquid
9 May 2024 11:09
I can reach it if I have it on the network that the rest of my containers are running on. But not when I run it on the seat internal one... Hmm logs for the mariadb show normal and ready for use
I think I have an idea to the problem. They must not be on the same network as I otherwise thought...
But if I try to add my normal docker network in the seat compose. The containers boot up on the network seat_mynormalnetwork instead of just mynormalnetwork
Warlof Tutsimo
9 May 2024 11:18
For information, I added network diagnose tools like nslookup and ping in last SeAT docker build. So you should be able your SeAT containers are able to dial properly
Also, double check firewall and credentials. It used to be common source of issues 😜
SneaktSquid
9 May 2024 11:20
Well I added my normal network and it seems to work now. Except now I am running into SSL handshake and bad gateway when trying to access the site
Warlof Tutsimo
9 May 2024 11:43
Bad gateway can simply means you're to hurry
Check your containers logs and be sure you get the SeAT logo in front container telling you the stack is ready to serve
SneaktSquid
9 May 2024 11:43
I have the logo and says ready to serve
I haven't been able to get the proxy compose to work, so at the moment I am trying without but I am thinking that wont work. I am a bit lost in what to do tbh
I have NGINX proxy manager routing to port 8080, so unsure what the error I am doing is
How would I go about locating the local ip for the seat installation? Right now I mostly want to confirm that it works. I am not so worried about accessing it through the domain at the moment
Because the IP of my unraid installation is not giving me a result
Dun Bar
9 May 2024 12:48
woke up today to 500 | server error
help
lol
recursive_tree
9 May 2024 12:51
can you send us your logs?
expose a port to the seat container
.docs.troubleshooting
Dun Bar
9 May 2024 12:52
ya
im there
recursive_tree
9 May 2024 12:52
should have a log section
Dun Bar
9 May 2024 12:52
im just looked at live eseye
recursive_tree
9 May 2024 12:52
you need to look at laravel logs for 500s
SneaktSquid
9 May 2024 12:52
Where would i expose that port? in the compose file?
Dun Bar
9 May 2024 12:52
ok
recursive_tree
9 May 2024 12:52
yes
SneaktSquid
9 May 2024 12:54
I would add that under the front service no?
recursive_tree
9 May 2024 12:54
yes
Dun Bar
9 May 2024 12:55
what am i looking for
SneaktSquid
9 May 2024 12:56
Stupid follow up here, I am not very used to compose at all....
Would i just add a section after "logging" that is called ports? and then just port:xxxx ?
recursive_tree
9 May 2024 12:56
post it here so we can take a look
Dun Bar
9 May 2024 12:56
dumb ?, how?
recursive_tree
9 May 2024 12:56
you can look at the traefik or peoxy docker-compose files to see how it is done
Dun Bar
9 May 2024 12:57
bare metal
recursive_tree
9 May 2024 12:57
copy&paste, preferably inside three ` backticks so it is formatted properly
SneaktSquid
9 May 2024 12:58
Don't understand what to do with the things in the dollarsign brackets..
recursive_tree
9 May 2024 12:59
they are there to use a .env variable inside the docker-compose. you can also replace it with the port
SneaktSquid
9 May 2024 12:59
logging:
driver: "json-file"
options:
max-size: "10Mb"
max-file: "5"
port:- :7575
recursive_tree
9 May 2024 13:00
you need to specify inside and outside ports, e.g. 8080:8080
SneaktSquid
9 May 2024 13:00
Does it have to be 8080?
recursive_tree
9 May 2024 13:01
the outside doesn't matter, but the inside must use the correct port. I think it is 8080, but I'm not sure
SneaktSquid
9 May 2024 13:01
https://pastebin.com/xCbtjsyY
Something like this then?
recursive_tree
9 May 2024 13:03
I think you got inside and outside the wrong way around and I think you need quotes: "7575:8080"
SneaktSquid
9 May 2024 13:03
Ah okay
Well, I am now also getting 500 | Server Error
But atleast I am getting a new error this time!
Dun Bar
9 May 2024 13:06
@user_614098468218339348 thanks again for your help. just did the ole classic turn it off and on again.(rebooted server)
site isup
recursive_tree
9 May 2024 13:15
That error basically tells that set couldn't connect to the DB. Maybe the DB crashed or something, so it makes sense that rebooting could have fixed it
SneaktSquid
9 May 2024 13:15
Same for me THANK YOU! It's working now, can access because of the port and I realized I had forgotten to give SeAT an appkey in env file.... But everything works now
New issue now 😄 Having issues with EVE Sign on now,
"{"error":"invalidrequest","errordescription":"The redirect URL does not match any of the configured values for this client."}"
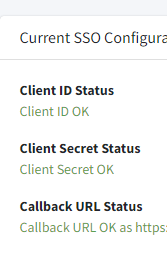
But everything looks to be configured correctly?
recursive_tree
9 May 2024 13:29
Well when you’re accessing it via exposed port and ip the redirect url changed from the one with a domain you used before. You have to update it on ccps side and in your .env
SneaktSquid
9 May 2024 13:30
Not sure if I understand, my callback url is set to
https://seat.domain.com/auth/eve/callback
On EVE and in the env
Obviously using my domain not actualy domain
recursive_tree
9 May 2024 13:31
Yes, but you just configured it to use an exposed port. This url does no include a port
SneaktSquid
9 May 2024 13:31
Hmm... It works now? But all I did was write this message on here, didn't even restart the service or anything... Maybe I was just being impatient
The port is being proxyied through nginx and cloudflare, so not exposed directly
Does it take a little bit before it fetches the ESI data or? Me and my buddy have succesfully logged in now, but it's not pulling anything ISK wallet, skills training, nothing.
I have it set to pull every single scope available
So sorry, I am litterally the most impatient person alive, it's pulling things now..
Raiden
9 May 2024 17:00
How do you add a specific price to a industry order in seAT
I have seat on a subdomain. if i wanted to do something on my main domain would SSL mess up seat ?
[LBS-C]Thess/Jarvande/Panymaris
10 May 2024 00:59
Secure Socket Layers (SSL) are a way to protect your domain. In this case your sub-domain points to your website. Where you main domain points is another story. The SSLs need to be separated if they point to different machines for brevity. Also, I am not a cryptography expert. It is possible to use an SSL to both, but this is expert level stuff.
Asrik
10 May 2024 02:19
I believe its called "Wildcard SSL/Certificate".
Crypta Electrica
10 May 2024 02:22
As long as you issued the right certs no.
Traefik will request certs specific to the subdomain so there is no overlap. So long as your top level site does the same you shouldn't have any issues. I don't believe there is any need to get fancy with wildcard or custom certs to make this work.
I have 38 subdomains with individual cert as well as a separate cert for the main domain site. Traefik / let's encrypt handles it all no worries
Astral
10 May 2024 18:27
We don't use SSL anymore though, We use TLS which is Transport Layer Security. Though for Wildcard certs you need to do DNS validation you can't get those without dns validation unless you pay and they provide the cert to you but there's no real point to pay for a cert in this day and age.
[LBS-C]Thess/Jarvande/Panymaris
10 May 2024 18:28
Yeah, my knowledge is rudimentary of the subject. I know enough to get by, lol.
Astral
10 May 2024 18:29
I have 6 domains on one ip, Using StrictSNI with dns validation as I can't be bothered to hit rate limits of generating subdomains..
Asrik
10 May 2024 21:58
I am not able to get my Corps logo on the signin page using the "Styling" help page. I thought maybe i can override the logo by adding the logo to the custom folder and add it as a volume.
"/opt/seat-docker/custom/mylogo.png:/var/www/seat/public/logo.png" i even tried ":/var/www/seat/public/web/img/logo.png" but that just broke seat...
what would be the best another another way of doing it?
Matt Falahe
10 May 2024 22:14
did u docker-compose -f docker-compose.override.yml -f docker-compose.mariadb.yml -f docker-compose.traefik.yml up -d ?
u can do it from custom like u did
or change traefik entry
in you docker-compose.traefik, there is this line:
"traefik.http.middlewares.seat-security.headers.contentSecurityPolicy=default-src 'none'; connect-src 'self'; script-src 'self' 'unsafe-inline' 'unsafe-eval'; style-src 'self' 'unsafe-inline' https://fonts.googleapis.com/ https://fonts.bunny.net/ https://snoopy.crypta.tech/; img-src 'self' data: https://images.evetech.net/ https://img.shields.io/; font-src 'self' https://fonts.gstatic.com/ https://fonts.bunny.net/; manifest-src 'self'"
replace it with this:
"traefik.http.middlewares.seat-security.headers.contentSecurityPolicy=default-src 'none'; connect-src 'self'; script-src 'self' 'unsafe-inline' 'unsafe-eval'; style-src 'self' 'unsafe-inline' https://fonts.googleapis.com/ https://fonts.bunny.net/ https://snoopy.crypta.tech/; img-src 'self' data: https://image.eveonline.com/ https://images.evetech.net/ https://img.shields.io/; font-src 'self' https://fonts.gstatic.com/ https://fonts.bunny.net/; manifest-src 'self'"
Astral
11 May 2024 02:05
Make sure you are downing and then upping and not just upping.
Asrik
11 May 2024 02:26
Still didnt pick up my corp image.. Not sure if the issue because im using Cloudflare tunneling.
I have been, "downing and uping, uping and downing, downing rebooting and uping" I have the same thing again with sudoing.
Astral
11 May 2024 02:29
Can you give the exact error?
Asrik
11 May 2024 02:29
There is no error. It just load Seat Logo instead of my Corp..
Astral
11 May 2024 02:29
You are adding the volume as read only too right?
Asrik
11 May 2024 02:30
I can confirmed that the css did load.
> version: "3.2"
>
> services:
>
> front:
> volumes:
> - /opt/seat-docker/custom/custom-layout-mini.css:/var/www/seat/public/custom-layout-mini.css
> - /opt/seat-docker/custom/custom-layout.css:/var/www/seat/public/custom-layout.css
Iv loaded just like that as said in the documentation.
Astral
11 May 2024 02:32
\\\yml
stuff here
\\\
Asrik
11 May 2024 02:37
Im sorry, but i dont quite follow what you mean but "yml stuff here".......
Jacob
11 May 2024 07:00
Hi I’m trying to setup notifications from seat when a new contract comes in to a corporation, but seat doesn’t seem to automatically update corporate contracts when it updates other contracts. Can anyone tell me what I would need to add to the schedule to get corporation contracts to update automatically?
Matt Falahe
11 May 2024 07:55
What address for Corp logo did u use?
Can u show us what is the error?
Asrik
11 May 2024 14:20
The same as on the documentations, i just swapped out the Corp ID.
.login-logo::before, .register-logo::before {
content: " ";
display: block;
width: 128px;
height:128px;
margin: 0 auto;
background-image: url(https://images.evetech.net/corporations/98239554/logo?size=128);
border-radius: 50%;
margin-bottom: 50px;
}
Matt Falahe
11 May 2024 14:22
ok then do traefik and that will fix.
Asrik
11 May 2024 14:30
I did it again, and it still didnt work
Matt Falahe
11 May 2024 14:31
Can u provide the error?
So we can see where is the issue?
Asrik
11 May 2024 14:37
I am bypassing Traefik. Using Cloudflare tunnel if that matters of not. In the Trafik logs unable to obtain ACME certification for domains and cannot get ACME client acme error 400, (but since i didnt use letsencrypt that would make sense). Thats the only error i see.
When i go to the login page of Seat, it shows everything as normal and the logo never changed to my corp logo...
I can confirm inspecting the page, it did load the css.

Looking at the log from front-1 it loading the SEAT logo
172.20.0.2 - - [11/May/2024:14:30:29 +0000] "GET /web/img/logo.png HTTP/1.1" 200 18607 "https://seat.test.space/home" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0"
i dont know if that matters or not.
If there is a specific error/log for you that you want me to collect, please let me know how.
Matt Falahe
11 May 2024 15:08
Inspect logo element. Maybe like in my case logo is there but under seat logo.
Asrik
11 May 2024 17:28
Its doesnt appear to be, unfortunately..
Astral
11 May 2024 19:13
You can use traefik with dns validation then connect via the tunnel to traefik with 443 specifying the origin cert if you want to use traefik for example.
Asrik
12 May 2024 00:41
Iv got the tunnel connect but how do I get the dns validation done?
Astral
12 May 2024 18:40
Or you can omit and just use http and don't go for LE and just let cloudflare handle all of that for you
VeritasLuxMea
13 May 2024 23:49
If you're using CloudFlare you need to clear the cache on their side if you make changes to the login-page.
Asrik
14 May 2024 00:13
Thanks ill will look into that...
Raven
15 May 2024 18:27
Is there an easy way to make the "Link Character" feature re-prompt for updated scopes in the default profile, as a means of updating people's scopes for their chars?
Right now the only way to update the scopes on a linked (non-main) character is to log out and then log in manually as that linked character. Which is very tedious
Actually I think it's this line creating the issue? The query for "first sessiontokens for this user" doesn't actually find the first character added to the user (doesn't sort by createdat)
https://github.com/eveseat/web/blob/5.0.x/src/Http/Controllers/Auth/SsoController.php#L74
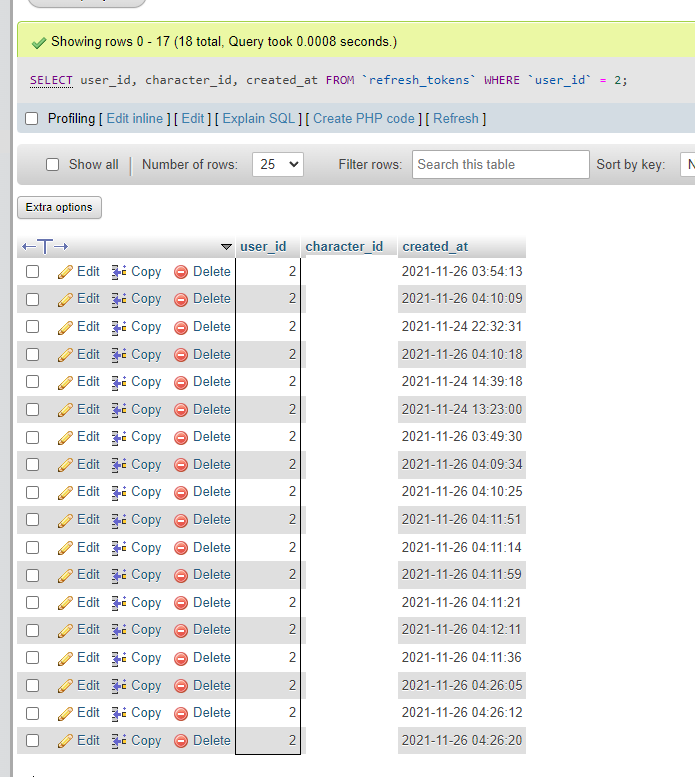
Confirmed: When I logged out and logged in as the first character_id in the natural order of the DB, which is not the first-added-char, and then linked some characters, it used the right scopes. ( https://discord.com/channels/821361165791133716/821361903933718589/1240409513744535662 )
Marazmatik
16 May 2024 00:53
This manual doesn't work for bare metal. https://eveseat.github.io/docs/styling/ wrong div class
And what can i do with this errors?
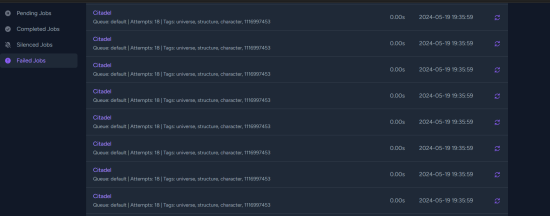
[2024-05-16 07:31:48] local.ERROR: Seat\Eveapi\Jobs\Universe\Structures\Citadel has been attempted too many times. {"exception":"[object] (Illuminate\\Queue\\MaxAttemptsExceededException(code: 0): Seat\\Eveapi\\Jobs\\Universe\\Structures\\Citadel has been attempted too many times. at /var/www/seat/vendor/laravel/framework/src/Illuminate/Queue/MaxAttemptsExceededException.php:24)
SnideBuffalo
17 May 2024 08:22
@user_301981661761896449 thanks for the reply and have a good one
Mystical_Dragon
17 May 2024 08:23
Thank you. Why do we not have the control over that information and ability ourselves? Why should it be left up to the seat administrator?
Crypta Electrica
17 May 2024 08:25
It shouldn't be in the user's control to delete data because that would defeat the intent purpose of the tool.
Mystical_Dragon
17 May 2024 08:42
its the intent of the tool? In what way?
Its MY information and MY data not the seat admins. If I leave a corp I should have FULL control over my data and nobody should have access to that past or present. Thats rather absurd to say that I relinquish control of my information.
If I decide to remove permissions and my characters, then the admins could choose if they should revoke roles (some discords are tied to seat verifications and permissions) or remove me from a corp if ive not left already.
This really makes no sense that even after I leave that my characters and information remains with the seat server. worse yet is the inability to join most corps without seat authorization. So if I have empire hauling alts that I want to protect their identity, leave a corp, (good or bad terms it doesnt matter) their identities are known to the seat admins and that data is there forever unless an admin choses to delete it.
Why so much power to the seat admins and so little to the people? I get it you have to watch for spies etc. Alert the admins with a security alert if permissions and characters are revoked so it flags it for them and they can determine if further actions are needed. However once I leave a corp and revoke permissions MY data needs to be removed immediately as it is MINE PERIOD.
Crypta Electrica
17 May 2024 08:54
I mean... You're wrong..
You own none of your data about your in game actions
recursive_tree
17 May 2024 11:14
you can always revoke the token so they at least don't get new data.
if you are really serious, you could probably sue them for GDPR violations or whatever law is applicable to your country
Mystical_Dragon
17 May 2024 14:44
Again what is the intended purpose of seat then. If the user has zero control over their data, cant keep others from seeing old data and cant delete their characters from it. it seems rather absurd tbh. why would anyone allow or push for this kind of nonsense.
it is MY data and I should have complete control over who can and cant see it. If I remove the permissions then ALL the data should be removed and past data should not be available anymore. Anyone who thinks this is a good idea is delusional.
VeritasLuxMea
17 May 2024 15:07
Unless your data has anything containing PII (Personally Identifiable Information) a request to delete said information is not protected under most laws. This is why I have a notification on my login page noting “By selecting Full SSO you are authorizing SeAT to obtain all available information from EVE ESI and will be active until the token is deleted”.
If however you have any PII contained in your characters, it would hold the maintainer(s) of that instance responsible to your request of deletion where laws are applicable.
At that point, the removal of PII itself could be done via anonymization and/or complete removal and the requester given proof of task completion.
Claw
17 May 2024 15:23
I don't want to be that guy, but you did have complete control over it. And then you authorized the scopes for the character as you added them.
It's not like it was forced from you. You didn't have to join that corp. That being said, any corp that doesn't check character history and what not using seat or another similar program isn't a corp worth being in to be honest.
The whole point is so people who admin the sites can check for spies, watch for people taking assets they shouldn't, and make sure the people trying to join them aren't complete idiots. You hiding your super secret hauler person is the exact thing the tool is designed to help corp directors work out, because sometimes it's not a super secret highsec hauler

Mystical_Dragon
17 May 2024 15:32
Actually the way its setup it keeps me from having control over MY data/information. If I decide to revoke permissions ALL data that was had should be removed. As it stands now you have to ask a seat administrator to delete that? thats absurd.
Actually it pretty much is forced upon us. Being in a good corp is essential to playing eve. A background check is important for that. However seat is far too invasive. I get it as i despise spies etc. However its absurd that people are ok with all their info out there and the admins always having access to it even once you leave. Why should we be forced to give up control over our info and data?
The way that it needs to be is if I revoke permissions the admins are notified of such. This also keeps them protected. However once I do that, the info I had previously authorized (pretty much under strong arm tactics or at least coercion) should be cleared until such time I do authorize it to be used again.
VeritasLuxMea
17 May 2024 15:32
Lets move this to the general chat
Jacob
17 May 2024 16:52
I have Contract Created with an affiliation for the Corp and a character within the Corp. The ui isn’t showing the contracts unless I manually click the update button. The characters contracts do get updated and pushed out but not the Corp contracts
Astral
17 May 2024 22:31
Imagine if you were a spy.. and you could auth but delete all the data.. Also it's NOT your data. It's OWNED by CCP.
Also future knowledge.. don't auth or join a group that uses any third party tools.. if you don't want someone having data..
Oh wait you were the one from a month ago.. You should've not accepted it a month ago..
All you..
Joseph Null
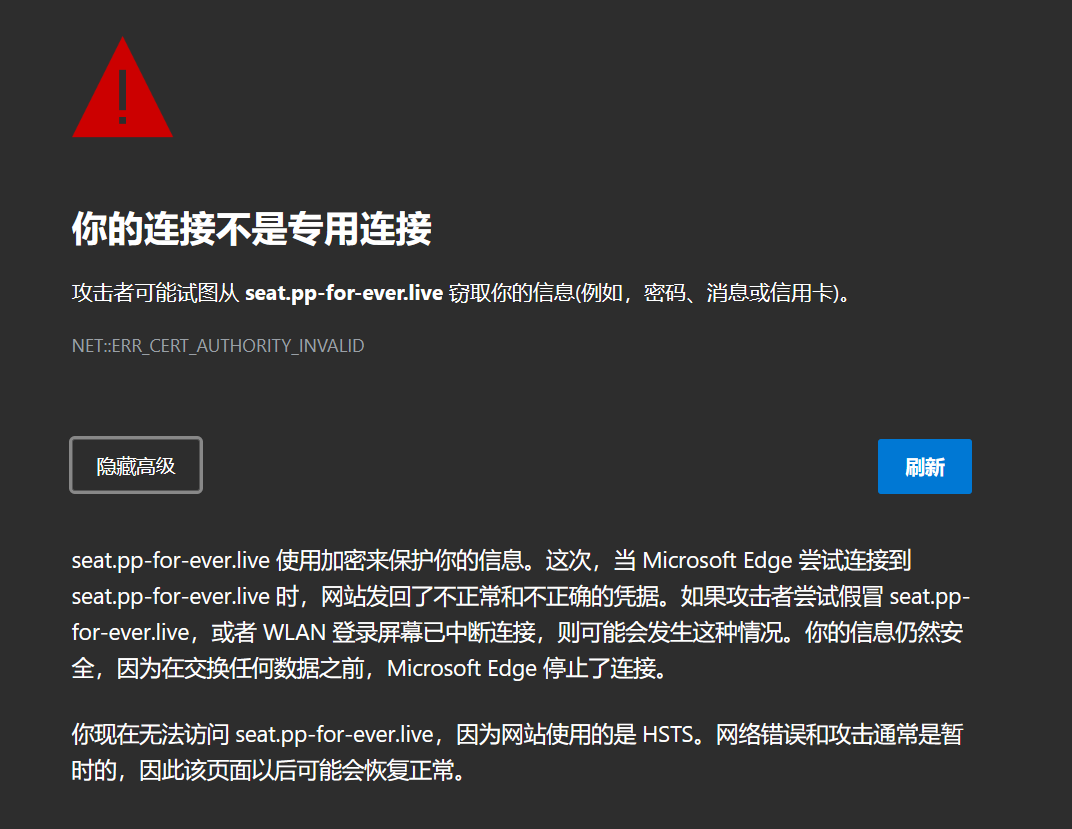
18 May 2024 11:01
how to activate SSL on seat5?
I get this when trying to use..
recursive_tree
18 May 2024 12:23
Can you switch it to english? But it looks like a self-signed cert
Joseph Null
18 May 2024 14:46
It's unable to resset language sr, but i try to translate it:
Seat-pp-for-ever.live uses encryption to protect your information. This time, when Microsoft Edge tried to connect to seat.pp-for-ever.live, the site sent back abnormal and incorrect credentials. This can happen if an attacker tries to impersonate seate.pp-for-ever.live, or if the WLAN login screen has lost connection. Your information is still safe because Microsoft Edge stopped the connection before any data was exchanged.
You can't access seate.pp-for-ever.live right now because the site uses HSTS. Network errors and attacks are usually temporary, so the page may return to normal later.
Astral
18 May 2024 16:51
Docker or bare?
Joseph Null
18 May 2024 17:59
docker
Astral
18 May 2024 18:01
Did you modify the proper stuff in the .env and also in the compose for the traefik part?
Or are you using your own traefik?
Joseph Null
18 May 2024 18:58
i just use the auto script,didnt change any thing
Astral
18 May 2024 18:58
Go into the compose for traefik and check the labels
Should be in /opt/seat-docker
Joseph Null
18 May 2024 20:22
already in.
Then>
Astral
18 May 2024 20:42
Check the traefik compose one for the LE lines
Raiden
18 May 2024 21:00
I added esi:killmail job and it keeps failing
Joseph Null
19 May 2024 05:02
LE line? What is it?
Astral
19 May 2024 05:03
Letsencypt line
or acme
Joseph Null
19 May 2024 05:41
acme.json? What should be make sure?
Astral
19 May 2024 05:52
yml
# ACME
- --certificatesresolvers.primary.acme.email=${TRAEFIK_ACME_EMAIL}
- --certificatesresolvers.primary.acme.storage=acme.json
- --certificatesresolvers.primary.acme.httpchallenge=true
- --certificatesresolvers.primary.acme.httpchallenge.entrypoint=http
Wibla
19 May 2024 10:22
So I'm an absolute idiot and can't document things I do to save my life. SeAT 4 "blade" install, I'm trying to tune it to fit on a smaller server, and tried to set the number of workers to 16 in the .env file instead of 32 to save some memory. balancing is set to auto, and it still goes to 32 workers, contributing to some swapping. Any ideas?
MrNoodless
19 May 2024 10:32
I assume you restarted?
Wibla
19 May 2024 10:32
of course
I tried to set it to 16 earlier on when I moved from 24Gb to 16GB ram, noticed it didn't "take", then left it alone because effort
Crypta Electrica
19 May 2024 10:33
Did you clear the config cache?
Wibla
19 May 2024 10:33
nope, that's probably it
let's give it some time and see how that works out
Crypta Electrica
19 May 2024 10:36
🙂
Wibla
19 May 2024 10:37
thinking about upgrading to SeAT 5 today, might just deploy a new VM and restore from database backup since this thing is positively ancient
and also test out keydb as a redis replacement... 🥳
that did the trick, tops out at 16 now
Joseph Null
19 May 2024 11:33
god, i get the problem, it's empty!
traefik is running, but I still cannot see the ssl
Wibla
19 May 2024 12:02
oh that's a fun one, I just tried to log in to a test install of seat 5 (bare metal) and it gives me a 404 after login 😄
or I just can't linux good, let's see...
looks much better now 🙂
Our current 4.0 install runs on debian ELTS, it's fucking ancient to say the least... reading the upgrade instructions, am I badly mistaken if the only two things I really need to upgrade is the .env file (with the app keys, callback url etc) and a database backup?
like dump that into a new install and upgrade the database to 5.0 format as described in the upgrade instructions?
InsanityProbe
19 May 2024 16:41
seat-connector/registration/discord/callback?code=gPfRcSmcUmFEAKdBybXQ0hdQ9gqsQ6&state=1epvengYlPK8IxZSfrNxjOSaCCaibqEdZFXSOC3a
I have a user getting a 500 error from with this url every time he attempts to link his discord to seat
Kiba
19 May 2024 16:42
I'd anticipate you'd likely want to dump it into a fresh 4.0 install on the new host (assumed since you mention debian ELTS) and make sure it works as expected, make sure all your plugins (if any) are available in 5.0, and then try an upgrade with the instructions. At least, that's how I did it a while back.
Wibla
19 May 2024 16:42
No plugins, so it's pretty simple to deal with, but that's also an option I'm looking at yeah
(but I have this fresh 5.0 install that works so it's tempting to blow away the database and test eve app .env id/key)
Marc
19 May 2024 16:44
I think you also have to make sure you've got the correct php version, but apart from that it was very straightforward
Wibla
19 May 2024 16:44
yeah
I'll clone this VM and see how it works 😄
Kiba
19 May 2024 16:51
I assume you're running bare metal. With the docs it seems to me if you just had the DB started, wiped it all out, import your 4.x DB and .env, update your .env for 5.0, then run the upgrade/migration under setup. Never run bare metal myself though so I'd probably say ignore my thoughts 😛
Wibla
19 May 2024 16:51
yes I'm a luddite
😄
Kiba
19 May 2024 16:52
I really dig the docker version of it since I can just slam it up on a new host in like 5 minutes if I needed to, import the .env and DB, point the DNS, and I'm done.
Wibla
19 May 2024 16:53
yeah I can see that
I self host, so spinning up VMs to do things don't bother me
Kiba
19 May 2024 16:58
It might be helpful to see what is in your laravel logs when the user tries.
.docs.troubleshooting
SeAT-Bot
19 May 2024 16:58
@user_214209749900722189, https://eveseat.github.io/docs/troubleshooting/
InsanityProbe
19 May 2024 17:06
Parently its working when he tries with a dif discord with an email rather than just a phone#
Wibla
19 May 2024 17:12
oh that's some annoying shit
currently restoring DB .. this takes fucking forever btw 😄
so we'll see how this goes shortly
OP success
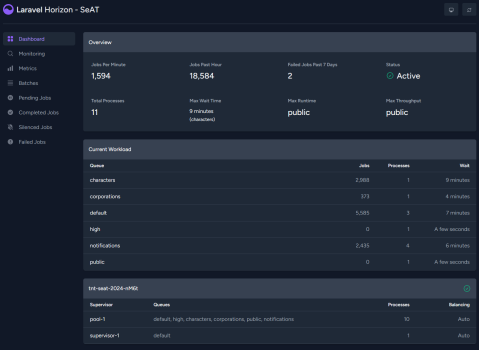
note to self: don't rugpull keydb to change the config mid-pull
it will fail ALL the jobs 😄
and also deadlock with neverending increasing failed jobs, how do I clear the entire queue and failed logs etc again? I need to write it down somewhere because I keep forgetting
Raven
20 May 2024 02:50
Should I be concerned about failures that look like excessive retries?
Illuminate\Queue\MaxAttemptsExceededException: Seat\Eveapi\Jobs\Universe\Structures\Citadel has been attempted too many times. in /var/www/seat/vendor/laravel/framework/src/Illuminate/Queue/MaxAttemptsExceededException.php:24
Stack trace:
#0 /var/www/seat/vendor/laravel/framework/src/Illuminate/Queue/Worker.php(785): Illuminate\Queue\MaxAttemptsExceededException::forJob(Object(Illuminate\Queue\Jobs\RedisJob))
#1 /var/www/seat/vendor/laravel/framework/src/Illuminate/Queue/Worker.php(519): Illuminate\Queue\Worker->maxAttemptsExceededException(Object(Illuminate\Queue\Jobs\RedisJob))
#2 /var/www/seat/vendor/laravel/framework/src/Illuminate/Queue/Worker.php(428): Illuminate\Queue\Worker->markJobAsFailedIfAlreadyExceedsMaxAttempts('redis', Object(Illuminate\Queue\Jobs\RedisJob), 3)
Wibla
20 May 2024 07:29
I've been seeing the exact same thing
Matt Falahe
20 May 2024 07:45
For me its with assets but with time it's slowly getting all the information pulled. I guess all the data cant be pulled at once.
If you need any specific info you can actually check what character and what station that is and then refresh it in seat UI.
Wibla
20 May 2024 08:03
wow, it really escalated overnight
got a bunch of this shit lined up too
one
php artisan queue:flush
seems to be racking up the same shit again, hm
from the shitty linux sysadmin side of things, the fact that failed jobs end up blowing up memory seems pretty bad...
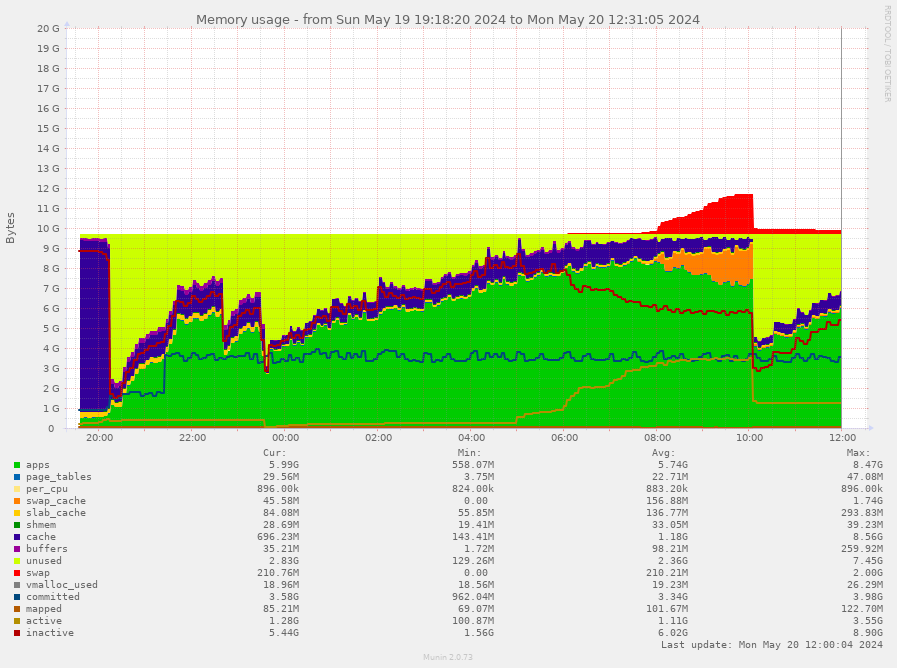
that's not good design, to put it mildly
recursive_tree
20 May 2024 10:08
when it happens, could you try to figure out what consumes the memory?
Wibla
20 May 2024 10:08
yeah I'll let it snowball a bit then look at what processes eat shit up
thinking back at some earlier discussion about redis, I suspect it's the redis that balloons out of control, I'll let it run unmitigated for a few hours and see what happens
this is SeAT 5 with eseye cache in redis as well
I didn't set maxmory on keydb 😄
that might be part of why it spirals
recursive_tree
20 May 2024 10:21
yes I also heard that seat redis sometimes spirals out of control. If that is the case, could you try to figure out which keys take up all the memory?
Wibla
20 May 2024 10:22
yeah I will
I've been fucking with keydb-cli and it has some pretty neat profiling tools
recursive_tree
20 May 2024 10:23
thanks. I unfortunately don't have an instance with the scale required to really observe these behaviours
Wibla
20 May 2024 10:24
yeah, I'll try to provide all the info I can
Crypta Electrica
20 May 2024 10:26
My understanding of this is that it is caused by the failed_jobs key, if you could have a look at that it would be great. horizon is configured as far as I can tell to use the database not redis for storage but we still see keys there
Wibla
20 May 2024 10:29
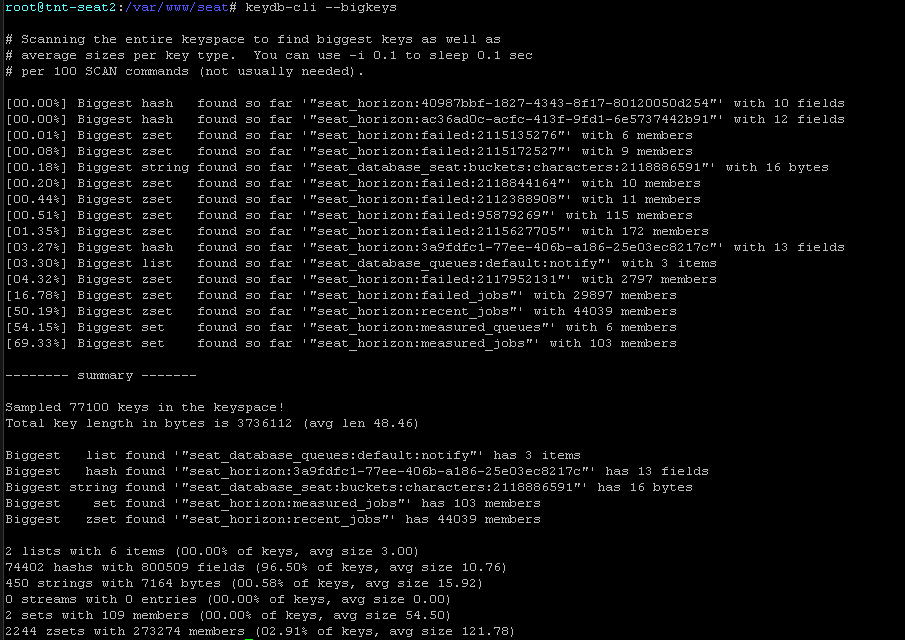
[04.32%] Biggest zset found so far '"seat_horizon:failed:2117952131"' with 2797 members
[16.78%] Biggest zset found so far '"seat_horizon:failed_jobs"' with 29897 members
[50.19%] Biggest zset found so far '"seat_horizon:recent_jobs"' with 44039 members
[54.15%] Biggest set found so far '"seat_horizon:measured_queues"' with 6 members
[69.33%] Biggest set found so far '"seat_horizon:measured_jobs"' with 103 members
😮
Crypta Electrica
20 May 2024 10:31
What do the percentages indicate?
Wibla
20 May 2024 10:32
I'm not entirely sure, let me look at the docs
think it's scan progress, but I'm not sure
doesn't seem to be struggling too hard
I'll add some more when it starts barfing all over itself
EQ11
20 May 2024 13:40
Hey folks, quick question: is there any way to filter squads by militia enlistment or any other attribute related to FW affiliation of a individual pilot?
recursive_tree
20 May 2024 14:33
I don't think so, but I'd say that would be a good addition
Wibla
20 May 2024 14:33
current status: HAPPENING
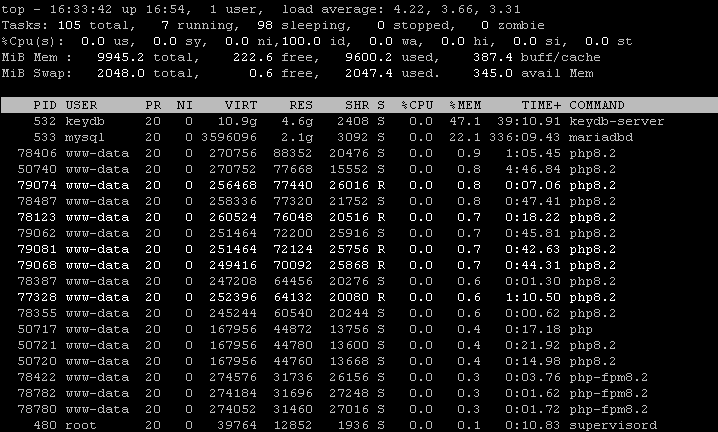
at 41k failed jobs
EQ11
20 May 2024 14:35
yea we're struggling to implement this as a FW corp. We can have other FW corps since all members are enlisted by default with the faction of the corp. But on the individual level, we can no lean on any scope leaving only solution a manual squad with diligent manual checking, which is not viable :s
Guessing this is an issue on the limitation of scope then? Is this something i'd have to bother CCP about?
recursive_tree
20 May 2024 14:36
It is mostly likely a seat limitation. Zkill has the faction, so it must be on esi
Moppa
20 May 2024 14:38
Yes, it is available at the Public Character and Character Affiliation endpoints
EQ11
20 May 2024 14:39
is there a scope i could add to try and filter by it?
it would save us SO MUCH work
Wibla
20 May 2024 14:40
re: above, I have now tried to set max memory 4GB in keydb and set it to evict when the cache is full, let's see how that goes
recursive_tree
20 May 2024 14:42
You best bet would be to implement a squad filter doing what you want. Filtering by a scope doesn't achieve what you want, as anyone can log in with any scopes you present as a login, even if a FW scope doesn't make sense for non-FW people
EQ11
20 May 2024 14:44
i see. Yea existing options in SeAT have no option for faction so i'm guessing we can sadly not filter by that. Unless there is some setting i can sort on the server to add faction somehow.
It's not the end of the world. We just have to approve corporations that are FW and can't get in people not in those corps automatically.
Not sure if any other FW corps have the same issues, maybe we're alone in this issue XD
Thing is, there is a faction attribute when i look at "all characters" and i can sort by faction. So i'm not sure why it's not an option in squads.
Wibla
20 May 2024 15:13
restricted keydb to 4GB, enabled LRU so it evicts old crud, very different pattern than before, seems it reserves the memory and keeps it active
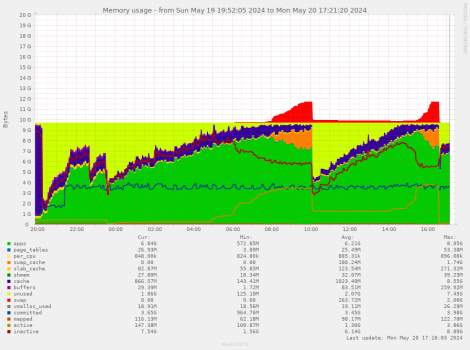
this keeps happening for me too btw, I wonder if this is a CCP / ESI issue
Myst
20 May 2024 18:44
I seem to be blind
how do you stop certain jobs?
Have a few that keep failing and dont actually care for them to run
Wibla
21 May 2024 04:11
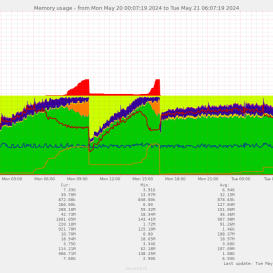
it looks like almost all the failed jobs are citadel jobs...
for no good reason
but setting max memory for keydb helped on system behaviour
recursive_tree
21 May 2024 04:40
Anything indicating why they fail?
Wibla
21 May 2024 04:41
"too many retries" shows up ... but nothing else
they shouldn't fail to begin with
so that shit is definitely weird
currently on my way to work atm, so not much I can do to dig into details
recursive_tree
21 May 2024 04:43
Nothing in laravel and eseye logs?
It’s just a suspicion, but it is roughly the behavior I‘d expect if the structure access cache fails. That resides in redis and you changed the redis setup, so it might be worth investigating it.
Wibla
21 May 2024 07:03
indeed
Akov
21 May 2024 07:24
so seat starts up and tries to access the citadel info for any citadel a toon or corp has assets in, you dont know if you have access to citadel info with out trying to access it, so if you have a lot of assets in structures you can no longer dock at, you get a lot of esi errors. I think those are stored in cache, so that if you ever try to look up again it its the cache and doesnt cause another batch of errors. LRU on the cache hits those citadel entries pretty often because theres no job that tries to update them again, so they are only active if some onen looks at their asset page, and that only catches the ones that actually show on screen.
i think the asset job only does lookups on new assets...which...if they are new, you probably have access
so for most usecases its fine, but the LRU eats the station cache
so you will get (number of unknown citadels with assets * number of folk that have assets there) errors every number of minutes until the LRU clears them
your millage may vary
a lot of think in there
Crypta Electrica
21 May 2024 07:30
I think the hard part here is that you are taking cache-eviction out of the hands of laravel, which can lead to unexpected impacts also.. Sure LRU gets rid of old 'cruft'. But who is to say that old stuff is not useful.
There should be other errors other than too many retries. That or the job was never attempted and just timed out.
The bigger issue I believe is that despite telling horizon to store failed_jobs in the DB, it is still using the cache
Wibla
21 May 2024 07:31
then you need to look at how you tag keys for eviction
and yes
Crypta Electrica
21 May 2024 07:31
For the horizon keys, we do not control eviction. That is done by horizon.
Wibla
21 May 2024 07:31
you can configure redis to evict keys that are marked for it first, iirc
ah yeah
Akov
21 May 2024 07:32
Its also notable, the number of failed jobs, could be 1 job retired 28k times or 28k jobs failed one time
Wibla
21 May 2024 07:32
yeah...
that thing is messy AF
(seen from my perspective as a shitty sysadmin 😄 )
Akov
21 May 2024 07:34
oh you're a sysadmin...Just add more ram then thanks
have you tried cloud ram? I saw it in ad at the airport
https://downloadmoreram.com/
Crypta Electrica
21 May 2024 07:35
In the case of these jobs the max retries is I believe 3.
Wibla
21 May 2024 07:35
trolololo
Akov
21 May 2024 07:35
😉
Wibla
21 May 2024 07:35
I'm trying to squeeze this install (with reduced job frequency) to fit in a smaller footprint
Akov
21 May 2024 07:35
True, was just stating that the counter can be misleading
Wibla
21 May 2024 16:48
https://pst.innomi.net/paste/qgvb3ku6s8fgv4p5fzxwx2og these are the first citadel errors from the 19th
root@tnt-seat-2024:/var/www/seat# cat storage/logs/laravel-2024-05-19.log |grep Citadel |wc -l
6911
root@tnt-seat-2024:/var/www/seat# cat storage/logs/laravel-2024-05-20.log |grep Citadel |wc -l
54070
root@tnt-seat-2024:/var/www/seat# cat storage/logs/laravel-2024-05-21.log |grep Citadel |wc -l
37569
link updated with when things started on the eseye side too
I just blew away the entire redis cache ... let's see how it gets on
(I do have a suspicion that me pulling the rug under the app by restarting the redis server in flight might have fucked things up ... so let's see what happens now)
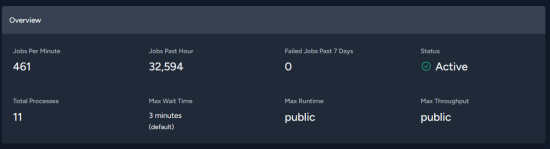
also tailing the logs it's hilarious how shitty the ESI really is 😛
503s and 504s galore on notifications
Crypta Electrica
21 May 2024 18:01
Yeah I have some patches in the works to improve the load performance of a number of jobs, including notifications and assets.
The pattern here is both expected and not... Citadels job fails a lot no matter what. No way around that as it's ESI design. We have a mapping stored in redis/cache that will blacklist citadels from characters where the call fails. If you are messing with the cache a lot or removing these keys then the jobs will keep failing.
Wibla
21 May 2024 18:03
in this instance I think I just broke it mostly on accident because of the rugpull
I'll let it run for a bit and see how it behaves
since I do 20 minute bucket refreshes, it'll take some hours to go through all the buckets, at least according to how I understand the job scheduling(?)
Crypta Electrica
21 May 2024 18:04
So the typical pattern is to see a lot of failures on start up while the blacklist is built up. The over time the errors tail off
Yeah 20m will take a while
There's 30 buckets to get through
Wibla
21 May 2024 18:04
2.4 complete refreshes per day or something...
Crypta Electrica
21 May 2024 18:05
Yeah. 10 hour cycles
Wibla
21 May 2024 18:05
I mean I can live with that kind of refresh rate
I also put a power meter on my server and looooooooooooooooool
letting SeAT spin as fast as it can ...
it uses a fair bit of power
vs tuning it down a bit
anyway, I'm going to keep fucking with this to see how it behaves, and I'm more than happy to share insights / info about how it behaves with the token load I've got
(though right now I'm going to let it run in peace for probably >24 hours)
Raiden
21 May 2024 18:47
So for some reason i deleted the esi:killmails job and readded it. But since readded it fails everytime , any help would be apreciated
Wibla
21 May 2024 18:50
and it barfed a ton of failed citadel jobs
Kiba
21 May 2024 19:24
If you delete it and restart the stack it should repopulate on its own. Default value is here.
https://github.com/eveseat/eveapi/blob/22bd98fbd72120cfa46aa18aa6ee4070a3f12018/src/database/seeders/ScheduleSeeder.php#L99
recursive_tree
21 May 2024 19:24
In your case, it might be worth to use a disk based citadel cache if redis capacity is limited
I already planned for that when writing the code, but it isn't ready
Wibla
21 May 2024 19:26
my redis cache is not full, it's sitting at 2.8GB / 4 GB
Raiden
21 May 2024 20:04
What do you mean by restart the stack ?
Kiba
21 May 2024 20:13
Down/up the docker stack. The seeder runs on each startup.
Raiden
21 May 2024 20:15
Ahh got it. Thank you. I'll try this out when I get home
Kiba
21 May 2024 20:16
Kinda surprised it fails on each execution though which makes me think there’s something off with the entry that you put back in, might be worth looking at the seeder code and making sure what you plugged in matches up, but otherwise might require looking at the logs.
Raiden
21 May 2024 20:29
Just to make sure. Delete the current esi:killmail and restart the docker stack should bring it back ?
Kiba
21 May 2024 20:40
That should be the case, yep. The seeder actually used to replace all entries on every startup but it was more recently changed to only seed missing items.
Raiden
21 May 2024 20:41
Thank you again
Kiba
21 May 2024 20:42
Down/up specifically, not just up. In case that wasn’t clear.
Raiden
21 May 2024 21:05
It was lol
didnt work
Seat\Eseye\Exceptions\RequestFailedException: failed to coerce value 'VALUE' into type integer (format: int32), 'killmail_id' is required in /var/www/seat/vendor/eveseat/eseye/src/Fetchers/Fetcher.php:344
nothing in my /var/www/seat as its in a docker image
sysdate
22 May 2024 07:49
Hi, How i can update my SeAT Eve API?
I already tried docker pull command. But it's not updated SeAT Eve API.
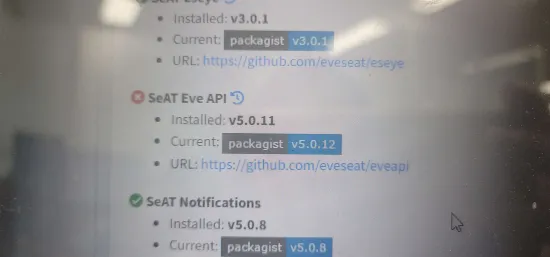
Crypta Electrica
22 May 2024 08:50
https://discord.com/channels/821361165791133716/821363152046129193/1242473065141764146
Working on it...
sysdate
22 May 2024 08:52
Oh thanks ♥
Wibla
22 May 2024 16:43
still getting a ton of citadel errors, I have switched back to regular redis to see if anything changes
will report back 🙂
@user_614098468218339348
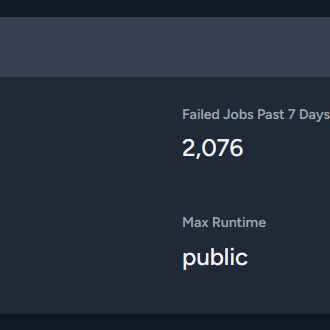
same config, but with redis and not keydb
it's sitting at 2.5GB / 4GB max memory too, so it's not evicting keys
18:00ish was the cutover
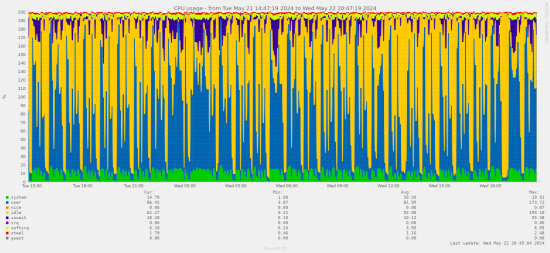
gonna let it run and see how it behaves overnight, bedtime now
Viper
23 May 2024 01:45
At what point did docker-compose become docker compose... and how come my system doesn't recognize it? xD
Updated docker-ce to see if I was just way behind (I was, but it didn't fix it)
Joseph Null
23 May 2024 01:46
How to release port 80?
Now I am using 443 as seat5, and I wanna use 80 for others, but seems seat5 still listening 80 and occupy it.
Crypta Electrica
23 May 2024 01:46
With newer versions of docker. For v5 we use docker compose and newer docker versions.
For v4 we still document using docker-compose
Viper
23 May 2024 01:46
I wonder if I need to reboot the OS to get it to apply the new version
docker -v returns 26.1.3
Crypta Electrica
23 May 2024 01:47
If using traefik it will still use port 80. As let's encrypt must be able to reach port 80 for the http challenge to issue you your certificates.
Depending on how it's packaged. You may need to install a package like
docker-compose-plugin to get it
Joseph Null
23 May 2024 01:51
I’am trying to use nginx to redirect request so that I can use subdomain to access different port. Is it possible to let traefix listen in other port?
Viper
23 May 2024 01:52
thank you! That helped! I've a few other issues, but I'll make an attempt to troubleshoot... like the -f flag not being recognized with the down command. xD
woo. Found my problem and fixed it. You fine folks in here are always fantastic. I try not to take advantage. ^^ (Well, kinda fixed it. The problem was me missing small details)
Gjallarhorn
23 May 2024 03:07
fresh bare metal install and fetching assets jobs are failing for both corp and characters, any idea what am i doing wrong here?
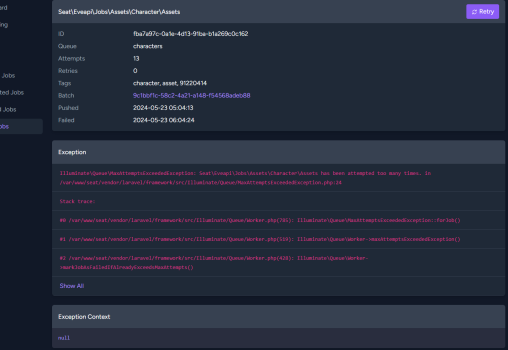
Kiba
23 May 2024 03:11
Most likely this - but may wish to verify - https://github.com/eveseat/eveapi/pull/404
Gjallarhorn
23 May 2024 03:14
i see that's for char assets, does it apply for corp assets job too ?
Crypta Electrica
23 May 2024 04:11
Yeah the fix is needed on both
Joseph Null
23 May 2024 04:34
@user_301981661761896449 I just comes up that, can we modify traefik config file and redirect seat.domain.com to 433 port, and doc.domain.com to 5000 port? Is it possible?
Crypta Electrica
23 May 2024 09:39
You cant have traefik not on port 80 as far as I am aware.. Is there something stopping you adding the doc subdomain under traefik? then it would get https also
Update your eveapi to get the fix
Gjallarhorn
23 May 2024 12:04
tyvm
Don
23 May 2024 16:23
I'm still seeing the issue after updating
oh another update.. sorry i'll try that
I've updated, seems to have resolved it for now. I am attempting to link another character, and its giving me error 500 | Internal Error
Ataraxia
23 May 2024 20:20
Heyo, wondering if anyone has any idea about where to start when running into gateway timeouts. I have a pretty barebones seat installation with no plugins right now. I see using docker-compose logs --tail 10 -f that the worker seems to be processing jobs fine. I'm using the docker installation with Seat 5, and basically just followed the tutorial. This installation has been running fine though a bit slow. I tried turning it off and on to no avail.
Any ideas appreciated.
Jacob
23 May 2024 22:27
I believe this might be related to the esi:update:corporations not being scheduled but when trying to add it to the scheduler I get Error validation.artisan
Crypta Electrica
23 May 2024 22:28
Check your laravel logs
.docs.troubleshooting
SeAT-Bot
23 May 2024 22:28
@user_301981661761896449, https://eveseat.github.io/docs/troubleshooting/
Crypta Electrica
23 May 2024 22:29
As in you are seeing gateway time-outs accessing the Web ui? Have a look at the cost of ntainer logs for the front container.
Ataraxia
23 May 2024 22:30
how might I look at the cost? FWIW I resized to a larger instance and it's up. I think my instance size was just too small and it was hitting max cpu.
Crypta Electrica
23 May 2024 22:31
Sorry autocorrect on my phone. I meant 'docker container logs for the front container'
Ataraxia
23 May 2024 22:32
ah in that case I did look at the logs for each container. The front container didn't seem to be making any logs after tailing the logs for a bit.
which does line up with the gateway timeout
Crypta Electrica
23 May 2024 22:32
No you do not need that job. Sorry in the other messages I missed your reply.
The biggest thing you would be looking for initially is had Apache started serving.
Ataraxia
23 May 2024 22:34
ah so after running for a few minutes I'm getting the gateway error again.
Tailing the front logs I can see requests so I know it was up
Jacob
23 May 2024 22:44
No problem anything else you can think that I should check?
Don
24 May 2024 00:20
enabled debug and got
Undefined property: Illuminate\Database\Eloquent\Relations\HasOne::$refresh_token
I can log out, log back in
I can auth another toon that hasn't been authed before
but linking another toon to a main account, the error occurs
Crypta Electrica
24 May 2024 01:08
Ahh Roger... I think I know what's going on yeah... I'll have to push a fix later tonight
Don
24 May 2024 01:27
sweet thank you!
Wibla
24 May 2024 15:06
ok, I'm pretty confident that something is wrong here now, with the citadel jobs ...
(that's a bog standard bare metal install, only change is that I use redis for eseye cache)
Xalkost
24 May 2024 15:34
Yeah, i've ran stuff on a new instance with a very small portion of tokens (around 50-100) and assets jobs tends to go poof (more than usual)
Wibla
24 May 2024 15:34
feels like a regression from 4.0 to 5.0
I also had a guy unable to add chars today, but I honestly don't have the bandwidth to try to troubleshoot that right now
Matt Falahe
24 May 2024 16:36
Is this after the recent update? I did it yesterday and failed assets just going up.
Wibla
24 May 2024 16:37
I did a fresh bare metal install the other day, then imported my old DB (and upgraded it)
Matt Falahe
24 May 2024 16:38
Yeah so we have the same issue most likely
Wibla
24 May 2024 16:41
sounds like it
Kiba
24 May 2024 17:05
Which version specifically are you on at this point? A few updates have gone in for assets over the past day or so.
Don
24 May 2024 17:12
I'm having issues as well, see above.
Wibla
24 May 2024 17:14
this is happening for me too, so yeah ...
some stuff going on
Matt Falahe
24 May 2024 17:32

Docker
Update done less then 24h ago
Wibla
24 May 2024 17:40
Crypta Electrica
24 May 2024 17:40
Was the person trying to link a char? If so then I'm aware of the issue there and should have a fix out within about 24h or so
Kiba
24 May 2024 17:41
Do you have any logs you can provide on it or what the messaging states?
.docs.troubleshooting
SeAT-Bot
24 May 2024 17:42
@user_214209749900722189, https://eveseat.github.io/docs/troubleshooting/
SeriouslyUnnamed
25 May 2024 01:59
using the docker compose file in seat 5, how do I expose maraidb ports?
iv tried adding the port, but it still doesn't get exposed
nvm, worked it out. networks internal setting
Matt Falahe
25 May 2024 06:56

usually those two errors are together
Wibla
25 May 2024 08:28
failed citadel jobs keep racking up
tmas
25 May 2024 15:32
Unfortunately these "job failed" log messages don't provide any details on the actual error that caused the job to fail. Can you try pulling logs with the instructions here? https://eveseat.github.io/docs/troubleshooting/#checking-log-files
The commands on that page will show you new errors, so you might have to wait for the error to happen again before it shows up. You can also run tail -n 5000 -f /var/www/seat/storage/logs/laravel-$(date +%Y-%m-%d).log instead of tail -f /var/www/seat/storage/logs/laravel-$(date +%Y-%m-%d).log to show the last 5000 lines of the logs right off the bat. I noticed there were a bunch of recent API timeouts in my logs, so it's possible that the issue is with ESI rather than SeAT
Wibla
25 May 2024 19:39
my gut feeling is that the cache for "oh that structure didn't work" ... isn't being built correctly, or isn't being checked
so it inflates failed jobs, and failed jobs fill up the cache for no good reason
Gjallarhorn
25 May 2024 19:41
OK, thanks for the clarifications, but it wasn't like this in the past, just saying....
Crypta Electrica
25 May 2024 19:41
And citadels are only fetched for a couple of reasons. Like having an asset in it. But remember that having an asset in a citadel can happen anywhere due to cargo drop mechanics. But ability to resolve the citadel is based on docking access. So if you have a lot of people with assets in places they can't access then this compounds
Has been for the whole of v5. And corps that way for v4
Gjallarhorn
25 May 2024 19:42
I believe you, haven't use it since v3 i think
Crypta Electrica
25 May 2024 19:42
The real problem here is having failed jobs in ram... I can find no reason why they should be, as we configure horizon to use the db not ram.
Wibla
25 May 2024 19:43
it's an onion of failures, layer one is that citadel job failures that should blacklist retries isn't working right, the second layer is that job failures end up where they shouldn't?
Gjallarhorn
25 May 2024 19:44
the alliances part doesn't bother me that much, but seeing all the corps instead of only those related to our chars is kinda annoying, i guess i have to get used to it
Crypta Electrica
25 May 2024 19:45
Prove the blacklist isn't working right and I'll go back there. I have checked countless times and always shown unique combinations of charids and citadel ids. Keeping in mind each time you clear cache you reset that blacklist.
Wibla
25 May 2024 19:46
this thing has been running for 24+ hours and the citadel job failures keep incremeting with 2-3k jobs every few hours
I guess it's been a couple of days now, actually
last restart of this stack was on Thursday
I limited redis to 4GB ram
so it doesn't spiral out of control
Crypta Electrica
25 May 2024 19:48
And your bucket schedule leaves you at a refresh rate of approx 10h right. So every 10h it will check all the citadels it was unable to resolve.
Let's say 4 people have stuff in 1 citadel that they cannot access. That will take 40h in order to get through before the blacklisf is fully populated.
And if it's limited at 4gb, what happens to keys when you exceed that
Wibla
25 May 2024 19:48
ok, let's see how it goes another couple of days
Crypta Electrica
25 May 2024 19:49
Once again, I'm not saying the system is perfect or doesn't need work.. I'm actively working on it in the little time I get.
Wibla
25 May 2024 19:49
I set it to
maxmemory-policy allkeys-lru
LRU = last recently used
maybe volatile-lru is better
Crypta Electrica
25 May 2024 19:51
I understand the policy. But keep in mind that allkeys-lru in this case is very likely going to target the citadel access cache as individual keys are not called often and have no expiry.
Wibla
25 May 2024 19:52
are other keys set for expiry?
Crypta Electrica
25 May 2024 19:53
Lots, anything that isn't needed permanently. Eseye cache all has expiry for example (if used). I believe horizon jobs other than pending (though would need to check)
Perhaps it may eventually even target the failed jobs
Wibla
25 May 2024 19:53
I can try to set it to volatile-lru
but let's see if it stabilises over the weekend first
that's a datapoint in itself
what config is the redis docker container set to, for docker builds?
Crypta Electrica
25 May 2024 19:55
Given your schedule and number of characters it may take a very long time to stabilise. Blacklisting only happens for a unique combination of charid-citid once per refresh cycle (ish)
I don't believe we evict. If redis fills you see lots of issues.
Wibla
25 May 2024 19:57
😮
Crypta Electrica
25 May 2024 20:00
Another thing you can look at to easier understand errors and loading is https://github.com/crypta-tech/seat-pulse
Wibla
25 May 2024 20:03
I need to check that out
LykosFerrum
25 May 2024 21:21
Hello I'm new at this and working on setting up the program and struggling with the call back process does that need a full website or just a host or what appreciate the help
Kiba
25 May 2024 23:07
You will most likely need full access to a VM or physical host to run SeAT. Most shared web services don’t provide proper access for the level you’d need to host the components.
Dun Bar
26 May 2024 03:07
when doing a general update on the migration part im getting this
{kind=link}
Crypta Electrica
26 May 2024 03:21
That isnt a table I am familar with... The core notification table was created in 2015 and has different fields.
Can you share the plugins you are using?
Dun Bar
26 May 2024 03:42
https://puu.sh/K7EdI/729644e68f.png
{kind=link}
and right now no jobs are being completed
Illuminate\Queue\MaxAttemptsExceededException: Seat\Eveapi\Jobs\Status\Esi has been attempted too many times. in /var/www/seat/vendor/laravel/framework/src/Illuminate/Queue/MaxAttemptsExceededException.php:24
i've put her back in maintence mode for now
I'm currently working 6days a week RL. Should I make a thread or forum post?
sysdate
27 May 2024 04:26
Is there any way to remove plugins including tables?
Because of my seat-billing data is bit weird. So i want to remove them clearly and reinstall.
seat-billing trouble
Joseph Null
27 May 2024 11:45
Does seat5 have any api that can use to quickly check if a pilot is connected to it?
For example output the name list by json
Matt Falahe
27 May 2024 19:19
Settings - > users - pick any and press user button on it. You will have option scopes to see.
I believe it's only for admins
Raiden
27 May 2024 19:48
So i accidently delted my esi:killmail job. after reentering it it fails everytime. I was told i should delete it and bring docker down and back up again and it should fix it. This didnt work. I curious if the esi:killmail job should be in a percticular order or something for it to work. Should i delete the other jobs and will this mess anything up ?
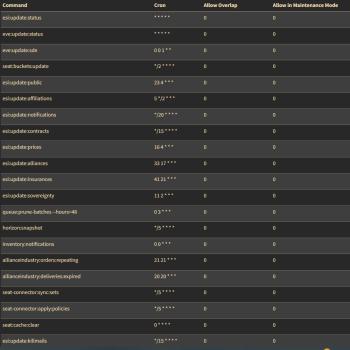
Oromit
28 May 2024 14:57
Hm, I really can't figure out what's wrong with Discord notifications since the update to SeAT 5...
They either don't fire at all if I add just one toon which should definitely get them.
Or if I add multiple toons for redundancy, they seem to fire once for every single toon or something
And even that makes no sense. I have two directors of the corp and the corp itself in the Notification Group. But we get a popped or re-fired moon pinged in Discord 6 times each.
Kiba
28 May 2024 15:03
As designed. If you have multiple characters setup for the notifications, or a corp, any character eligible that gets the notification will fire a unique message. Probably best to just use a single CEO or director character for specific notifications for structures, etc. Seat does not aggregate or deduplicate them.
Oromit
28 May 2024 15:03
Well, I tried that. Then I didn't get any notifications at all.
Marc
28 May 2024 15:03
So thats why we got 8 „New Application“ pings per application 👀
Oromit
28 May 2024 15:03
Does that character need to regularily log in and clear its notification queue or something?
Kiba
28 May 2024 15:04
Yes.
No. You may have one or more failing notification job if the character is getting the notification in game, you have the right notifications and character setup in the settings, and the token is valid.
Oromit
28 May 2024 15:06
no notable amounts of failing jobs right now, and the character is myself