SeAT - ❓-support - Page 4
Vladimir_Vladykin
15 Jun 2024 14:03
the list of ESI accesses for all characters this
Kiba
15 Jun 2024 15:32
What version? There was a fix I believe a few weeks ago to fix a condition where linking a character would sometimes result in the wrong scopes being applied depending on the condition.
https://github.com/eveseat/web/releases/tag/5.0.11
Vladimir_Vladykin
15 Jun 2024 18:14
| Vendor | Package Name | Installed Version |
| ------------- | ---------------------- | ------------------------ |
| eveseat | api | 5.0.0 |
| eveseat | eseye | 3.0.1 |
| eveseat | eveapi | 5.0.13 |
| eveseat | notifications | 5.0.8 |
| eveseat | services | 5.0.7 |
| eveseat | web | 5.0.13 |
| cryocaustik | seat-hr | v2.0.0-alpha |
| recursivetree | seat-billing | 5.0.0 |
| recursivetree | seat-prices-core | 1.0.1 |
| recursivetree | seat-rat | 2.0.0 |
| recursivetree | seat-transport | 2.0.1 |
| recursivetree | seat-treelib | 2.1.2 |
| warlof | seat-connector | 3.0.0 |
| warlof | seat-discord-connector | 6.0.1 |
| warlof | seat-teamspeak | 6.0.1 |
| ccp | eve_online_sde | sde-20240612-TRANQUILITY |
I update regularly
Mctwisp (John)
15 Jun 2024 20:32
any can help me with this issue? can't acces to logs
Don
15 Jun 2024 21:35
Question, for discord connector does it remove roles from people that are not authed as well?
Astral
16 Jun 2024 00:04
If they have roles and aren't connected no.. They don't get roles taken away..
Just derole everyone when you go to force authing
Don
16 Jun 2024 00:05
got it
thank you
Astral
16 Jun 2024 00:06
If they are connected.. then yes if they don't fall into the rules they'll get derolled
Don
16 Jun 2024 00:36
Sorry one more question, for the notifications is there any way to define when they are sent?
Specifically low fuel notifications
Asrik
16 Jun 2024 01:46
You have to go to the Notifications Group under the Notifications and create a group. After you can specify what alerts..
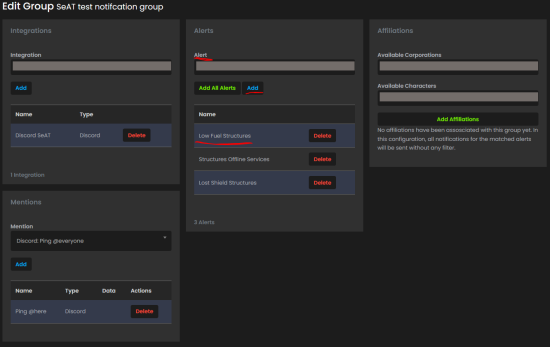
Don
16 Jun 2024 01:49
Yea, I set that. Removed fuel to less than 48 hours and haven't received a ping yet.
Crypta Electrica
16 Jun 2024 01:51
Have you received the notifications in game? As that is the notification source.
Don
16 Jun 2024 01:58
Ah ok, so no I didn't yet. I did wait for a good half hour or so
Matt Falahe
16 Jun 2024 03:24
Notification in game is less then 24h fuel
Don
16 Jun 2024 03:25
Hmm that’s a bummer
Lucia Denniard
16 Jun 2024 11:20
anyone know how much space you'd usually need on the volume mounted for seat storage?
and which containers actually need it, between web, cron and worker
recursive_tree
16 Jun 2024 15:18
I think a DB without any tokens is on the order 1GB, mostly for the SDE and market orders. The more tokens you have and the longer it runs, the more it will grow though. The shared storage directory for laravel is required on all containers. On my dev install it is 4.2 GB: - 1.2 GB eseye cache(grows with tokens, this install only has a few character)
- 2 GB logs, can be optimized, but occasionally balloons if something goes wrong
- 0.8GB temporary storage for the sde while it is being installed
- some various bits and pieces
it will work with separate volumes, but some things are broken
for example:
- the web UI logs viewer will only see web logs
- when scaling beyond one frontend worker, seat-inventory resources like images will only be stored on one frontend worker, giving you a 50/50 chance of the image loading
- when scaling beyond one esi worker, the esi cache will be split in two. It won't break seat, but it might anger CCP since you won't respect etags in 50% of the cases. However, you can switch to the experimental redis esi cache. that might us a considerable amount of RAM though.
seat is very io heavy, so probablly suboptimal
Lucia Denniard
16 Jun 2024 15:28
NFS would be the sane option
recursive_tree
16 Jun 2024 15:28
you can try it out, I'd also like to know the results. NFS would probably be fine, I'm sure S3 is not
Wibla
16 Jun 2024 15:28
NFS can work fine as long as the storage backend is fast enough
recursive_tree
16 Jun 2024 15:28
on S3, you'll get terrible performance and a high bil
Lucia Denniard
16 Jun 2024 15:29
the NFS would probably just come from another server with an SSD, in the same DC
luckily I don't care about multi-AZ seat
recursive_tree
16 Jun 2024 15:29
sound fine, at least for a small instance. Once you start scaling to 4000 tokens like wibla, it might be a different story
Lucia Denniard
16 Jun 2024 15:30
it'll probably only be 1000 max
Wibla
16 Jun 2024 15:30
it also depends on the token update schedule
if you keep it at default ... oww
recursive_tree
16 Jun 2024 15:32
also, if you do a non standard deployment like on k8s we kind of expect you know what you are doing and that you can help yourself, at least to a certain degree. I don't want to discourage you though
Lucia Denniard
16 Jun 2024 15:33
yeah I know
I've been running seat on k8s for like 3 years
I'm just rewriting it all on helm atm
I was also running with redis swapped out for kafka before
which is pretty overkill and I don't really recommend it
Wibla
16 Jun 2024 15:38
damn 😄
yeah
Astral
16 Jun 2024 15:39
Are you using like minikube or something weird? over a full cluster?
Lucia Denniard
16 Jun 2024 15:39
nah the digitalocean one is just shit
and I am too cheap to run hard knocks services on google cloud
Astral
16 Jun 2024 15:39
Ah I don't touch cloud hosts for k8s wouldn't touch a presetup cluster either
Wibla
16 Jun 2024 15:39
yeah no
lol
also VPS is a total crapshoot for SeAT as far as I've seen
Astral
16 Jun 2024 15:40
If I am to use it it's something I'm doing bare install for and switching out modules.
(k8s)
Lucia Denniard
16 Jun 2024 15:41
I did run my own one for a while but it was a bit of a headache
and it was quite easy to just switch it all over to digitalocean
cross-region k8s is just a mistake
but yeah if anyone else needs one, this does everything except shared disks https://github.com/andimiller/helm-seat
Astral
16 Jun 2024 15:54
I mean people do cross region weirdly..
Kwa Zulu
16 Jun 2024 18:58
I have trouble doing this unfortunately, after extensive googling etc
Old v4 solution was defining in the compose file:
ports:- 127.0.0.1:3306:3306
I have the same btw, lots of jobs erroring on retries, related to structures
Wibla
16 Jun 2024 19:48
Yeah...
I get a few thousand failed jobs per hour heh
recursive_tree
16 Jun 2024 19:48
please send me a screenshot of how the job is failing
and how many tokens do you have?
Kwa Zulu
16 Jun 2024 19:52
3950
ill send some screenies
Don
16 Jun 2024 21:09
Seems the linked character issue is back
Astral
17 Jun 2024 00:13
No same scenario networks is just for intercontainer communication and the ports section is only if the host needs to access a container
Just make sure to down and up
Remote host you could use an ssh tunnel to have 3306 appear locally at say your home remotely without opening it to the world to do work
[--ACE]Greviouss
17 Jun 2024 06:49
hey guys - im generating like 10 gb of logs a day... how can i trim that down?
FeiBam
17 Jun 2024 07:26
Because I made a lot of customizations to the docker-compose file of seat 4.0, I plan to upgrade to seat 5.0. I decided to back up the database of seat 4.0 and then delete the entire volume, container and network related to seat 4.0. This is equivalent to completely reinstalling seat 5. However, after restoring the database, seat cannot start normally. The error is
front-1 |
front-1 | INFO Routes cached successfully.
front-1 |
front-1 |
front-1 | INFO Running migrations.
front-1 |
front-1 | 20220107124200createjobbatchestable ........................ 2ms FAIL
front-1 |
front-1 | In Connection.php line 829:
front-1 |
front-1 | SQLSTATE[42S01]: Base table or view already exists: 1050 Table 'jobbatches
front-1 | ' already exists (Connection: mysql, SQL: create table job_batches (id
front-1 | varchar(255) not null, name varchar(255) not null, total_jobs int not n
front-1 | ull, pending_jobs int not null, failed_jobs int not null, failed_job_i
front-1 | ds text not null, options mediumtext null, cancelled_at int null, cre
front-1 | ated_at int not null, finished_at int null, primary key (id)) default
front-1 | character set utf8mb4 collate 'utf8mb4unicodeci')
front-1 |
front-1 |
front-1 | In Connection.php line 587:
front-1 |
front-1 | SQLSTATE[42S01]: Base table or view already exists: 1050 Table 'job_batches
front-1 | ' already exists
front-1 |
front-1 |
traefik-1 | time="2024-06-17T07:14:52Z" level=error msg="service \"seat-front\" error: unable to find the IP address for the container \"/seat-docker-front-1\": the server is ignored" providerName=docker container=front-seat-docker-d13ea536d48444498762c7b43316622b081e50b81dfeb03ede7508e2dc1f8aad
What should I do now?
Astral
17 Jun 2024 07:59
Bare or container?
[--ACE]Greviouss
17 Jun 2024 07:59
bare
i dumped the logs folder - I had to get it back online and that was the consistent issue and i had just found it - yea i know.. i know... sigh.... imma give it a day to build up something and see what its tripping over
FeiBam
17 Jun 2024 08:59
fun look like i need Manually delete the table
job_batches table
recursive_tree
17 Jun 2024 09:01
you cannot import a seat 4 database into seat 5.
FeiBam
17 Jun 2024 09:01
i am not import
recursive_tree
17 Jun 2024 09:02
better question: Why are you generating 10GB of logs per day?
you can just delete the file btw
[--ACE]Greviouss
17 Jun 2024 09:02
i did
that was the mistake cause now i cant read why lol
😄
whatever it is will trigger again im sure - i did recently just update to 5 over 4 so well see
FeiBam
17 Jun 2024 09:03
If I cannot import the data of Seat 4.0, does it mean that all my data will be lost?
recursive_tree
17 Jun 2024 09:04
What were you exactly doing? Errors like this can happen in the following situation:
1. take backup of seat 4
2. shut seat 4 down
3. install seat 5
4. restore backup of seat 4 into seat 5
5. get the crash you described
[--ACE]Greviouss
17 Jun 2024 09:05
the odd part is seat seemingly working fine
FeiBam
17 Jun 2024 09:06
I deleted all seat4.0 docker-compose
downloaded the new seat 5.0 docker-compose and loaded my own service
Then it still shows that job_batches table already exists
This is my docker-compose
[--ACE]Greviouss
17 Jun 2024 09:07
[previous exception] [object] (PDOException(code: HY000): SQLSTATE[HY000]: General error: 1205 Lock wait timeout exceeded; [previous exception] [object] (Seat\\Eseye\\Exceptions\\RequestFailedException(code: 502): Bad gateway at /var/www/seat/vendor/eveseat/eseye/src/Fetchers/Fetcher.php:344)
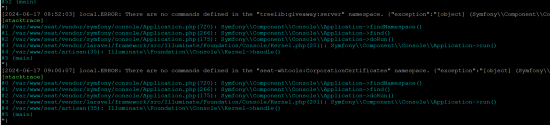
that last one atleast i know what its complaining about heh
FeiBam
17 Jun 2024 09:10
OK, it seems that the problem is caused by the existence of mariadb-data volume
so i need delete it? XD
There is no difference between this and reinstalling Seat 5.0
[--ACE]Greviouss
17 Jun 2024 09:10
fml
some days....
recursive_tree
17 Jun 2024 09:13
mariadb-data contains the database. if you delete it, your data will be gone. And since your backup is from seat 4 as I understand, you won't be able to restore it, because a seat 4 backup must be restored on a seat 4 instance
FeiBam
17 Jun 2024 09:14
So a major version update will definitely discard the data of the previous version.
recursive_tree
17 Jun 2024 09:14
no, you can keep the data. Just follow the upgrading guide
[--ACE]Greviouss
17 Jun 2024 09:14
thats what i did
its probably my install went semi stale during the last corp down time window
reinstall all the same to me np really
FeiBam
17 Jun 2024 09:20
So I should install a clean seat 4 and then restore the backup
then docker-compose down
and then download the docker-compose for seat 5
Astral
17 Jun 2024 09:30
NGL, This looks an absolute dumpster fire for bringing compose files up.
FeiBam
17 Jun 2024 09:33
just work fine only job_batches error lamo
Astral
17 Jun 2024 09:35
I mean this looks like you took one service per container to compose level..
FeiBam
17 Jun 2024 09:40
I didn't touch any files except docker-compose.traefik.yml
Astral
17 Jun 2024 09:40
It looks so fragmented and annoying at that point worse to manage in the end if they are in seperate locations
Honestly if your traefik is configured properly you should never have to touch it minus adding more entrypoints or to update it
Like version wise not file wise
FeiBam
17 Jun 2024 09:43
lamo this is seat 5
Astral
17 Jun 2024 09:44
And?
FeiBam
17 Jun 2024 09:45
lamao
Astral
17 Jun 2024 09:45
And..? the files you shown are more fragmented then seat v5.
FeiBam
17 Jun 2024 09:46
I don't know what you want to say. If it is not managed like this, what should we do? (
Astral
17 Jun 2024 09:49
I mean are you using all those compose files or it it just the traefik one in the end alongside the seat ones?
FeiBam
17 Jun 2024 09:51
Yes I used all the files, absolute-order.com works fine, but seat is stuck in migrations
( OK
good
Optical Deon
17 Jun 2024 10:26
Is v5 production ready or better stick to v4 as it more stable and have more supported plugins?
FeiBam
17 Jun 2024 10:36
You now have to update to V5 because the required cores for V4 are no longer updated
Crypta Electrica
17 Jun 2024 10:45
@user_917754750840242217 the problem you ran into was because your upgrade was a little out of sequence. you brought up v5 front container before you restored your database. This caused the migration to run and create all your tables.
In order to correct the issue, down your seat stack with the
-v flag in order to remove the volumes. This wipes the database so you can start afresh.
Then start the DB only (service name is mariadb), restore your v4 backup into that database, only once the backup is installed, bring up the rest of the stack
recursive_tree
17 Jun 2024 10:48
By now, v5 is more stable and recommended unless you need a specific plugin only available on seat 4. Seat 4 isn't developed further, the focus is on seat 5
Tachi
17 Jun 2024 10:54
would you guys happen to have the steps to migrate SeAT4 (docker) DB into a SeAT5 (bare) DB?
Crypta Electrica
17 Jun 2024 11:00
Process is identical with just a quick switch at the middle. So to take your backup use the commands for docker, then for restore use the bare commands. The backup file is identical
Can I ask why the move from Docker to bare?
Tachi
17 Jun 2024 11:43
there are some custom stuffs we want to do with seat for our corp and some minor changes that would work for us.
FeiBam
17 Jun 2024 14:51
front-1 | Generated optimized autoload files containing 7977 classe
front-1 | In UnableToCreateDirectory.php line 18:
front-1 |
front-1 | Unable to create a directory at /var/www/seat/public/web/css.
wtf ...
Astral
18 Jun 2024 01:23
You can just use volume's to modify sections of seat..
Ncc-1709
18 Jun 2024 16:55
nvm the env is messed up
FeiBam
18 Jun 2024 17:48
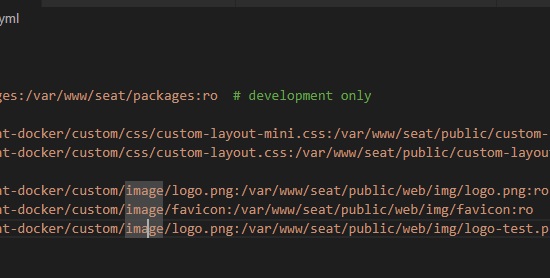
Can I create a new repository or docker image for seat?
Aims to provide more customizable options
use traefik router to proxy all static file
like logo favicon
@user_76781846418956288
Because the static files of seat front are dynamically decompressed by PHP
Docker volume and mouth will cause insufficient PHP permissions
So I want to rely on traefik's router function to reverse proxy files like logo css
I can't think of a better solution at the moment
Kwa Zulu
18 Jun 2024 19:46
I noticed a few characters that were added into Seat 2 days ago didn't contain any data. After running php artisan esi:update:characters <character_id> they ended up in a few-hours long queue (seems to be mainly caused by the structure calls that are failing/retrying that Wibla and I have been observing and that is being looked into)
I now cleared the whole queue and stopped running any buckets, then the command line update works instantly
recursive_tree
18 Jun 2024 20:07
this makes sense. basically seat is overloaded with structure calls on large installs. by removing most of the esi load, it is no longer overloaded
We should really put out a fix or at least a mitigation
Kwa Zulu
18 Jun 2024 20:08
Yeah, I'm now running one bucket manually to see what happens
Wibla
18 Jun 2024 20:10
that would be lovely yeah
mysticalbz
18 Jun 2024 21:10
super quick question... what would cause a server 500 error on.....just 1 character
everyone else works it seems.. but 1 guy.. 500 server error
recursive_tree
18 Jun 2024 21:10
it can mean many things. please send us your logs
.docs.troubleshooting
SeAT-Bot
18 Jun 2024 21:10
@user_614098468218339348, https://eveseat.github.io/docs/troubleshooting/
mysticalbz
18 Jun 2024 21:11
thanks.
Kwa Zulu
18 Jun 2024 21:26
Btw after finishing one bucket of 134 tokens I end up with 166 failed jobs
Ncc-1709
18 Jun 2024 21:45
server has been up 8 mins...
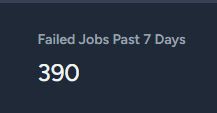
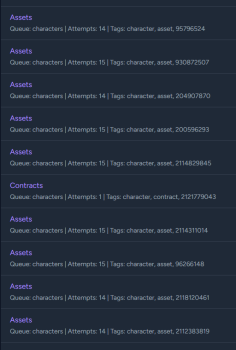
Kwa Zulu
18 Jun 2024 22:00
No clue if this helps
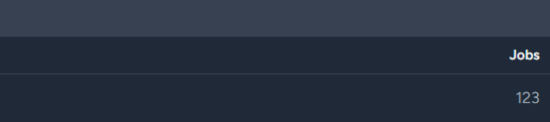
FeiBam
18 Jun 2024 22:31
look like work fine!
Don
18 Jun 2024 22:49
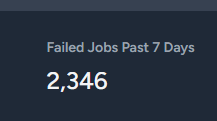
not sure either
Anyone know why this would be happening?
Crypta Electrica
19 Jun 2024 01:28
.docs.troubleshooting
SeAT-Bot
19 Jun 2024 01:28
@user_301981661761896449, https://eveseat.github.io/docs/troubleshooting/
Don
19 Jun 2024 04:06
Well shoot
Wibla
19 Jun 2024 04:27
That's pretty normal
Vladimir_Vladykin
19 Jun 2024 12:19
did you manage to fix this problem?
Ncc-1709
19 Jun 2024 19:55
so still getting spammed by the memory full issue
the env and php.ini are both set -1
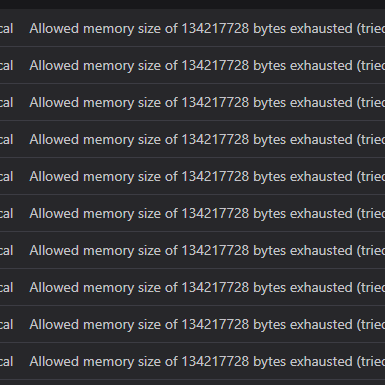


Crypta Electrica
20 Jun 2024 05:59
Which job is this coming from?
Ncc-1709
20 Jun 2024 13:05
{
"exception": "[object] (Symfony\\Component\\ErrorHandler\\Error\\FatalError(code: 0): Allowed memory size of 134217728 bytes exhausted (tried to allocate 2131672 bytes) at /var/www/seat/vendor/laravel/framework/src/Illuminate/Database/Connection.php:430)
[stacktrace]
#0 {main}
"
}
Tachi
22 Jun 2024 10:20
does any of the devs/admin have the schema for the Database?
Optical Deon
23 Jun 2024 07:03
does any one have a default schedule for Seat v5, or how to drop schedule to default values?
Crypta Electrica
23 Jun 2024 14:42
Once again this doesn't tell us which job this is coming from. Is there anything in logs surrounding this that indicates a job class that was running?
I mean it can be generated whenever we need it. I don't know that we have anywhere that lays it out atm. What are you looking for?
You mean like here: https://github.com/eveseat/eveapi/blob/5.0.x/src/database/seeders/ScheduleSeeder.php#L42
Can't remember if there's others off the top of my head
Optical Deon
23 Jun 2024 14:55
is it the way force setup from this seeders?
just run one line, or one command?
Crypta Electrica
23 Jun 2024 14:55
Are you running docker or bare?
Optical Deon
23 Jun 2024 15:19
Docker
Crypta Electrica
23 Jun 2024 15:20
If docker the seeder runs every time on boot
But it won't replace an existing entry to revert it to default.
So if you want to revert a line to default, then remove it and restart your stack
Optical Deon
23 Jun 2024 15:23
Can you give piece of advice for performance tuning?
What to monitor and how adjust?
Crypta Electrica
23 Jun 2024 15:31
By default seat is configured to pull data as fast as ESI cache will allow. No point going faster.
To slow things down the. Bug ticket item to reduce is the buckets update. There are 30 buckets, with one queued every time the cron job runs. So the default of every second minute means all updates from buckets are on a one hour cycle. Reducing the update rate of buckets will alleviate load on the server
Wibla
23 Jun 2024 15:32
that one change can really affect load
as I found out 😄
Crypta Electrica
23 Jun 2024 15:32
Most esi updates are queued from within buckets
Optical Deon
23 Jun 2024 15:35
So this picture looks ok, from your point of view?
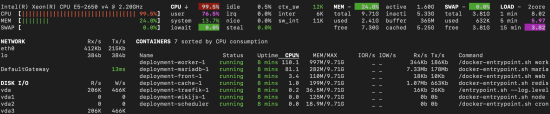
Crypta Electrica
23 Jun 2024 15:37
There's no easy way to know... Are you getting through your queues in horizon? If so then you have enough performance to match your queue settings
Optical Deon
23 Jun 2024 15:39
Max wait here is bad sign, right?
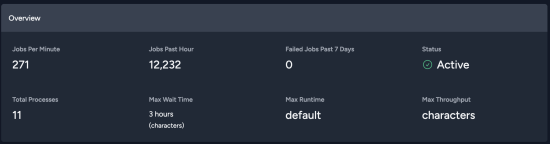
Crypta Electrica
23 Jun 2024 15:41
Yes but no... Horizon can be bad at measuring this metric well... At the most basic level, have a look at the failed jobs count (though in v5 citadels makes this a bit weird anyway).
The best thing to look as is the number of jobs in each of the queues. As long as they don't balloon out of control over say 20m or so then you are not in a bad place
Best case scenario is there is times when you have no pending jobs
Wibla
23 Jun 2024 16:19
how many tokens and what kind of server is this running on, btw?
Optical Deon
23 Jun 2024 16:52
how many tokens and what kind of server
Illuminate\Queue\MaxAttemptsExceededException: Seat\Eveapi\Jobs\Universe\Structures\Citadel has been attempted too many times. in /var/www/seat/vendor/laravel/framework/src/Illuminate/Queue/MaxAttemptsExceededException.php:24
SustainedCruelty
25 Jun 2024 15:03
Hey everyone, I'm having trouble understanding how the discord connector is supposed to work.
I've got a squad filtered by a corporation that allows users to view the connector (which works fine). Then under access management in the connector settings I've mapped a filter for the same corp to a discord set. Is there anything else I have to do for the bot to apply the roles? Right now it's not doing anything. I've also set up the cron job for refreshing the discord roles which doesn't throw any errors either

User and set are linked but no roles are applied
The bot role is also at the top of the server roles
recursive_tree
25 Jun 2024 15:24
How many tokens do you have?
Optical Deon
25 Jun 2024 15:33
around 2.2k
recursive_tree
25 Jun 2024 18:00
It is normal that citadel errors out more than other jobs since we cannot know if a character is allowed to access a citadel without making an esi call and risking an error. You are a rather large instance and the errors might add up a bit. We are currently developing some mitigations for this.
Wibla
25 Jun 2024 18:14
I am testing some of that, and it seems to work
Optical Deon
25 Jun 2024 18:44
but ccp had to update character with field allowed or not see citadels. this one field could reduce api calls a lot
rather than you develop some hacks with exception handling
recursive_tree
25 Jun 2024 18:46
hmm? I don't quite get what you mean
Optical Deon
25 Jun 2024 18:51
maybe I do not fully understand the root cause issue with Citadels. Nevermind
to run more workers in dockerized deployment, I can just scale worker container or I need some additional steps?
recursive_tree
25 Jun 2024 19:26
the usual way is to scale QUEUE_WORKERS in your .env. This basically adds more processes on a single machine. Once you max that out and want to add a second machine, in principle you should be able to scale worker containers, but I don't know of anyone actually doing that, it is also pretty much untested
only thing I can think of is you need to ensure that the
seat-storage volume is synchronized across containers, as it holds the esi cache. Alternatively,you can switch the eseye cache to redis. In that case, not having a shared seat-storage will only break a few thing like the web ui logs viewer
If you actually end up going the route of multiple worker containers, I'm happy to help with fixing issues
The citadel jobs mainly fetches the name of citadels. The root cause is that there is no way of knowing if you will get an error from ccp without sending a request that might cause an error. There is no endpoint to check for ACLs or something like that. The assets endpoint can even report citadels you are not allowed to dock and therefore unable to get tne name of the citadel. Esi is a clusterfuck
Raiden
25 Jun 2024 20:04
So when using discord notifications for low fuel on my structures it send it 3 times. Any known fix ?
Kwa Zulu
25 Jun 2024 20:13
Tie it to a specific character instead of a corporation (you prob have 3 chars that get that notification?)
Raiden
25 Jun 2024 20:21
yea i thought it was that. thank you ill try that instead
Pymous
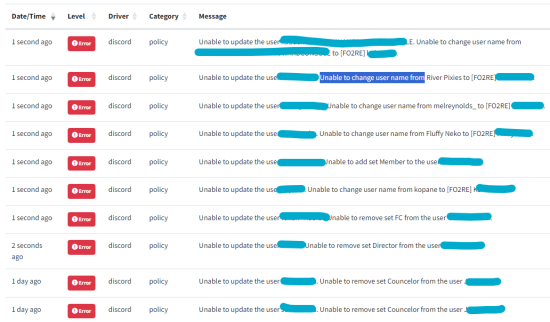
25 Jun 2024 20:32
Hey guys !
I'm trying to use Discord Connector, but I seems to have some issue with my mapping/settings, because I get a bunch of errors saying that the plugin cannot apply a role or change a name :
Raiden
25 Jun 2024 20:38
Make sure your bot is above all other roles in your discord settings
and ensure it has all admin privlages
Pymous
25 Jun 2024 20:52
That did the trick ! Thanks Raiden !
Raven
26 Jun 2024 00:31
Still seeing tons of errors on SeAT, I reset to the default seeded schedule and it's still been rough.
It's consistently errors like this: Seat\Eveapi\Jobs\PlanetaryInteraction\Character\PlanetDetail has been attempted too many times but for different jobs across the board.
Raiden
26 Jun 2024 00:55
pc specs ?
Wibla
26 Jun 2024 04:06
sounds like you have overloaded your machine, adjust seat:buckets:update ?
Jay's
26 Jun 2024 04:32
I deployed SeAT on kubernetes and I have 2 instances of Seat replicas of Seat workers and it works quite well. But I'm using redis for cache because my k8s volume manager does not handle locked files
Raven
26 Jun 2024 06:14
I9 64gb ram
Doesn't matter where I install seat, if I have this many jobs going (about 400 seat users), it consistently has this error.
The jobs are prevented from running because they run too often. Or so says that error message.
No CPU or memory issues.
It's not timeout or some other failure. The error is "you call this too often". I'm just using the default schedule.
Raiden
26 Jun 2024 06:16
Have you tried to add more workers in your .env file ?
Raven
26 Jun 2024 06:16
Why would more workers solve the "you are running too many jobs" error?
It's literally not even retrying these jobs. First job is a failure.
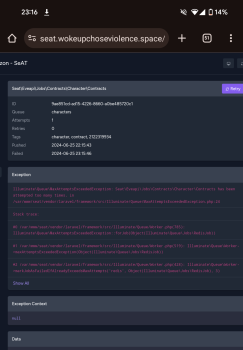
It's as if the limit of "how many times you can run this job" is ignoring the fact that it's for different characters each time. So if you have LOTS of characters, you're screwed for no reason.
Kiba
26 Jun 2024 06:20
I think it may end up getting bottlenecked if the job gets queued and sits for longer than an hour, and then you'll get the "tried too many times" which feels like more of a "timed out" to me rather than necessarily tried too many times.
More queue workers = more parallel jobs, in theory should reduce that occurrence.
Wibla
26 Jun 2024 06:27
it's basically this
up the workers
particularly if you're running this on a beefy machine like an i9
seat:buckets:update you can also change this from the default 2 minutes to 5 or 10 without any ill effects except slower updates
Kiba
26 Jun 2024 06:30
Yep, either more workers or reduce bucket update frequency or both at least in my limited experience - but I don't have anywhere near as many tokens as Wibla does 😛
More workers will definitely result in higher utilization of resources, but shouldn't be of any concern on an i9.
Wibla
26 Jun 2024 06:31
the next pain point is generally disk IO
Crypta Electrica
26 Jun 2024 12:13
No, its not a "you call this too often" its a "this job was attempted at a time after the configured timout" error
So if you dont have enough workers you wont be able to process the jobs before they timeout
Optical Deon
26 Jun 2024 12:46
Is it possible to increase this timeout?
Do you have some advices for this pain point? Move DB to separate disk, etc?
I have a lot free RAM memory around 10GB, so one more question, is it possible somehow use this free memory, to reduce disk access? Maybe for caching or etc.
Crypta Electrica
26 Jun 2024 12:52
Not currently. But the timeout is an hour.. So if you cannot complete the jobs in that time then you need to either decrease your number of jobs, increase workers etc...
There is an option to place the eseye cache into ram instead of disk. So long as you dont run out of ram that is not a bad approach
Optical Deon
26 Jun 2024 13:01
by using Redis? or just create disk in ram, and mount this path inside container?
Crypta Electrica
26 Jun 2024 13:01
redis sorry yeah
Optical Deon
26 Jun 2024 13:01
How to enable it?
Crypta Electrica
26 Jun 2024 13:02
https://eveseat.github.io/docs/configuration/env_file_reference/
set the environmant variable ESEYECACHEDRIVER to redis
Raven
26 Jun 2024 14:18
@user_214209749900722189 @user_131158012831203328 thanks for your responses.
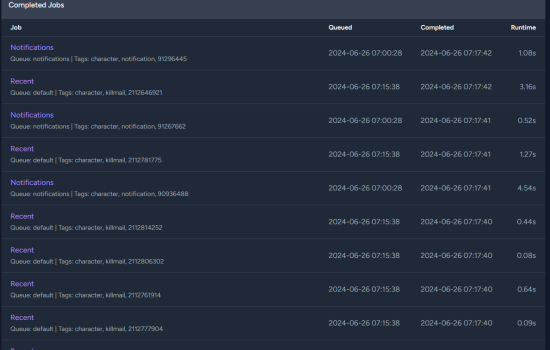
What would I expect to see in Horizon (if anything) that proves that this is actually the case? Metrics and completed jobs both kinda show that jobs are being processed quickly. There is no indiciation that jobs are sitting in queue for a long time.
Ncc-1709
26 Jun 2024 14:20
so, i just tried this and.. the site is loading so much faster, and server cpu load has dropped a chunk
Kiba
26 Jun 2024 14:23
Mostly in my experience just that the queue itself is stacked up with jobs constantly to where you’re basically always at a deficit with the bucket updates. So every 2 minutes, a new set of jobs come in, but the previous jobs haven’t yet completed.
I’m sure someone else with more experience on a larger instance can provide more clarity, but at least with my instance I’ve been keeping an eye on queues and adjusting workers up as needed to make sure the queue can basically nearly clear before the next batch goes in.
Ncc-1709
26 Jun 2024 14:26
it snowballs
you need to slow it down so the queue can clear before more are dumped into it
Wibla
26 Jun 2024 14:47
You need to monitor it during tuning, or it will get away from you quickly
Kiba
26 Jun 2024 16:26
I'm curious - are there any configuration variables or ways that more workers could be dedicated to a specific queue outside the default? For example, if I'd like to dedicate, let's say, 3 minimum workers to Notifications to ensure they process in a timely manner even if other queues are busy, would it be possible to do this?
Of course, with the understanding that QUEUE_WORKERS will need to be adjusted up to avoid problems.
Ncc-1709
26 Jun 2024 17:29
Optical Deon
26 Jun 2024 18:49
does anybody try to tune mariadb?
Viper
27 Jun 2024 01:50
I have a member (my CEO actually) whos token keeps "going missing". When I get him to re-auth, it never fully updates his character. It does pull some things, but skills and such never update, then after a few hours the token expires. He claims he is not removing access, and I am certainly not deleting it. Are there any other instances where a single characters token can just... disappear?
Astral
27 Jun 2024 01:56
Like his character data goes poof? and is he authing with the full scope or a limited scope?
Tokens can also be revoked if someone does a password reset
Viper
27 Jun 2024 01:58
What character data pulls remains. The Token simply invalidates. He states he is not changing his password or otherwise invalidating it purposefully. It is a full scope auth
Wibla
27 Jun 2024 06:04
that's pretty sus
Kiba
27 Jun 2024 06:15
Agreed that I’ve never seen that sort of behavior as long as your jobs are running properly, there is the third party EVE token site as well which is the only thing not mentioned yet. If for some reason he’s revoking access (button is named “delete app” which is a bit misleading) there it will revoke the token.
https://community.eveonline.com/support/third-party-applications/
You can also have him login to his character and verify that your application name shows up there. If your app is not there under the character with the bad token, there’s no valid token. If it’s there - well, might be worth looking at logs for further clues.
Matt Falahe
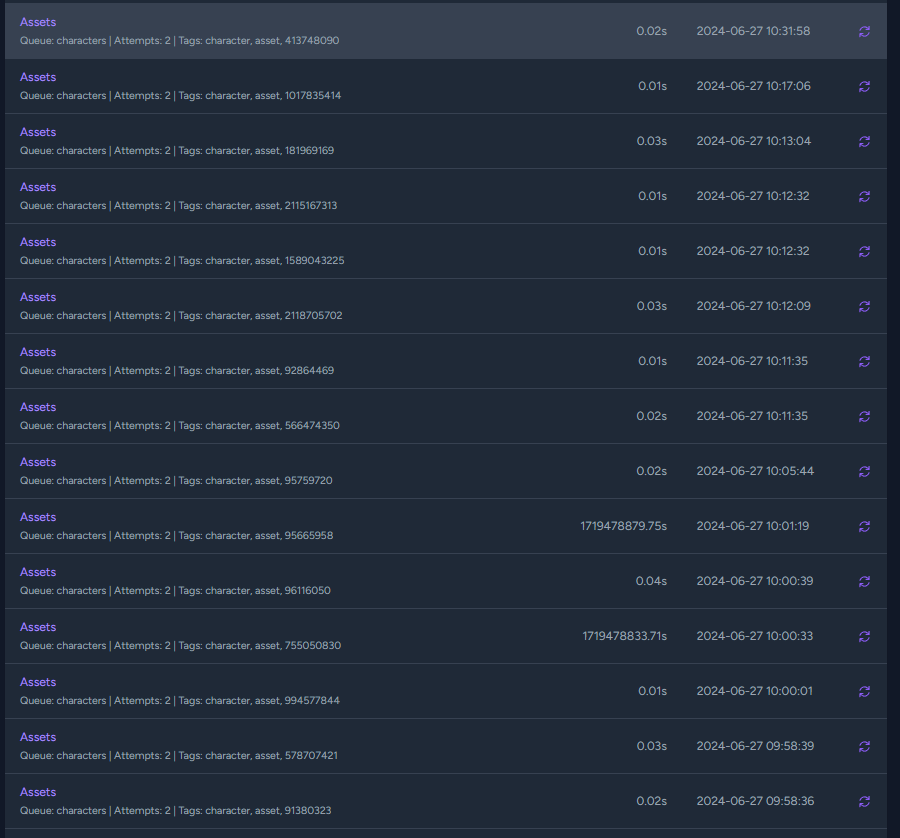
27 Jun 2024 09:46
hi,
I'm getting a lot of update assets failed jobs. I am set on 16 workers.
Any idea how to solve this MaxAttemptsExceededException issue?
Kwa Zulu
27 Jun 2024 11:40
does he by any chance go by the name Bobby Tables?
Lucia Denniard
28 Jun 2024 11:10
any of you happen to know which MySQL table stores character<->user links?
ah it's
refresh_tokens
just had to trawl through most of the database to get there
Nany1419
28 Jun 2024 11:30
How to set limits in permission management to allow viewing characters only from one's own corporation.
MrNoodless
28 Jun 2024 11:56
Underrated comment
Wibla
28 Jun 2024 11:58

Grasume
28 Jun 2024 22:07
Fresh install and i get 500 errors what could it be ?
on docker
whats weird logs show
front-1 | 172.18.0.3 - - [28/Jun/2024:22:05:25 +0000] "GET /auth/login/admin/bQ2X7pVlMFVoHODBhxhV6Xzbxhwiv5Ck HTTP/1.1" 500 13493 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
rip im a dummy and forgot to update app_key
Wibla
28 Jun 2024 22:19
it happens 🙂
learning by doing
or learning by fucking up
Grasume
28 Jun 2024 22:19
now if i can figure out the restore
issues
as thats failing for some reason
Astral
28 Jun 2024 22:40
Don't make it too long either..
Grasume
29 Jun 2024 01:42
Im having a brain fart
if i took OLD db and moved it to new and made new eve Dev creds
would that revoke the old tokens ?
Ncc-1709
29 Jun 2024 01:48
making new dev token revokes all
Astral
29 Jun 2024 03:27
Just add the new scopes domain it should go through the list of valid callbacks
Keyzi
29 Jun 2024 19:13
hello, i have some trouble with api.
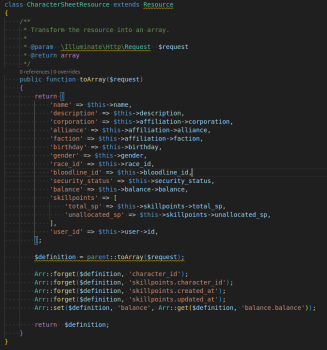
handler /api/v2/character/sheet/{id}.
for some characters i have got response with 500 status code.
Attempt to read property "balance" on null
"exception": "[object] (ErrorException(code: 0): Attempt to read property \"balance\" on null at /var/www/seat/vendor/eveseat/api/src/Http/Resources/CharacterSheetResource.php:73)
can you help me fix it?
Vladimir_Vladykin
29 Jun 2024 19:21
Does anyone have any ideas on how to solve this problem? Or has someone already managed to solve it?
Asrik
30 Jun 2024 01:23
Could it be possible that person revoke all granted ESI permissions??? Just a thought..
Matt Falahe
30 Jun 2024 01:58
I believe thats the issue with publicdata scope only
Keyzi
30 Jun 2024 08:53
any way, an incomplete set of character data should not cause errors when generating a response. It may be necessary to check whether an object is initialized before retrieving its values.
Vladimir_Vladykin
30 Jun 2024 09:41
No
Whinis
30 Jun 2024 12:26
So I had a ticket open.... 7 months ago.... wow... and started testing a custom fix for assets and it seems that now corp assets are just never updating at all
not sure exactly how to search for just corp asset jobs
Wibla
30 Jun 2024 12:28
spot the SeAT 5 upgrade 😄
Kwa Zulu
30 Jun 2024 18:19
I noticed there was an update with several citadel call fixes, did that work out for your server @user_131158012831203328 ?
Wibla
30 Jun 2024 18:23
I haven't updated
didn't see that heh
Vladimir_Vladykin
1 Jul 2024 05:00
yes, it looks like it only concerns the public part, but it still makes me paranoid 🙂
Crypta Electrica
1 Jul 2024 12:24
It would be worth not having the custom fix anymore as the jobs ahve been improved in the core application
Whinis
1 Jul 2024 12:36
Alright it has been removed. Still cannot figure out why my corp assets are not updating at all
Crypta Electrica
1 Jul 2024 12:36
Are your jobs completing? And do you have a token of someone with access to corp assets
Whinis
1 Jul 2024 12:37
I am checking the token now because I was told it was but now checking I am less sure. And yes all jobs appear to be completing
ill get back to you once a Director or someone gets on. While I have that role I have not logged into eve in...... 12 years
Crypta Electrica
1 Jul 2024 12:45
In v5 in horizon you should also be able to go back through the 'Batches' and find the batch named for the corporation and that will tell you how the jobs for that corp went
Moppa
1 Jul 2024 12:45
I'm getting errors posting Discord notifications for POCO reinforcements.
Client error: `POST https://discord.com/api/webhooks/XXX/YYY` resulted in a `400 Bad Request` response:
{"exception":"[object] (GuzzleHttp\\Exception\\ClientException(code: 400): Client error: `POST https://discord.com/api/webhooks/XXX/YYY` resulted in a `400 Bad Request` response:
{\"embeds\": [\"0\"]}
at /var/www/seat/vendor/guzzlehttp/guzzle/src/Exception/RequestException.php:113)
Crypta Electrica
1 Jul 2024 12:47
Is there any more detail to that log?
Moppa
1 Jul 2024 12:47
Just a long stacktrace but no details
Context
{
"embeds": [
"0"
]
}
I'll try to run it in my local dev and see if I get anything more
Whinis
1 Jul 2024 12:56
All I see is killmails, how would I confirm a corp token ?
Crypta Electrica
1 Jul 2024 12:57
Eaiser way, go to the users tab, find a director for your corp and check the scope on their director tokens to make sure it includes assets
Whinis
1 Jul 2024 12:59
Ya confirmed esi-assets.read_corporation_assets.v1 and yet via batches all I see are killmail request
Crypta Electrica
1 Jul 2024 12:59
in your scheduler do you have seat:buckets:update
Whinis
1 Jul 2024 13:01
ya, looks like every 2 mins
Moppa
1 Jul 2024 13:39
Found the issue.
My notification has "aggressorAllianceID": null but this section returns a field with
https://github.com/eveseat/notifications/blob/5.0.x/src/Notifications/Structures/Discord/OrbitalAttacked.php#L73
{
"name": null,
"value": null,
"inline": true
}
So I'm moving the if-statement outside since returning just produce an empty field.
@user_301981661761896449 https://github.com/eveseat/notifications/pull/101 Fixes the above issue
Whinis
1 Jul 2024 16:49
checking the scheduler log seat:buckets:update is running without errors
seat:buckets:list only shows 1 bucket, and its not any of the tokens I need
Akov
1 Jul 2024 17:13
logic check: Some one that has a deactivated account, shouldnt be able to login to seat
and if they were already logged in, it should log them out
ReadYY
1 Jul 2024 17:18
sooooo if i find that the failed_jobs table is using 54 gigabytes
is that good? 😄
QUESTION: can i just clear the whole table (while seat is down, only db running) and start seat again?
Kiba
1 Jul 2024 17:27
I can’t check for sure right now but I’m fairly sure the seat maintenance job clears that table.
ReadYY
1 Jul 2024 17:47
yea might be something wrong with the config i just took over that instance and the 54 gigs are 2 months of failed jobs
looks like it deletes failed jobs after 2 months
Kiba
1 Jul 2024 17:48
They do grow over time just due to regular failures but there may be some other items to review if everything is resulting in failure, I run the job once a month on mine.
ReadYY
1 Jul 2024 17:48
kk
i'll just delete the older half for now
could you tell me what job that is?
cause all my seat instances seem to have the same problem (i think i nailed it down to since i upgraded to seat5)
Kwa Zulu
1 Jul 2024 19:42
never had problem to just TRUNCATE that table while running
ReadYY
1 Jul 2024 19:42
oh so you just completely clear the table itself
well thats one way to do it 😄
Kwa Zulu
1 Jul 2024 19:43
I do have a custom query that groups by error type but yeah on GBs thats not going to be fun so I usually just truncate it first
ReadYY
1 Jul 2024 19:43
wierd thing is since i upgraded to SeAT5 not a single failed_jobs entry got deleted...
i would have guessed those have a limited lifespan but appears not
@user_398925835794645002 @user_76781846418956288 sorry for poking you but i don't know what to do 😄
so situation is that ever since i upgraded my seat instances (i run 3 different ones) to SeAT5
the failedjobs table grew now i wonder if there is some sort of mechanism to keep this table in check
what i found is queue:prune-batches --hours=48 in the schedule page is there something like this for failedjobs aswell?
the table grew to the size of 55 GB in two months.
Kiba
1 Jul 2024 19:59
seat:admin:maintenance iirc
Kwa Zulu
1 Jul 2024 20:01
Yeah queue:prune-batches only prunes job_batches I believe
Utama
2 Jul 2024 00:41
Hey guys, Im extremely new to this and I'm trying to spin up a server for my corp. I cant seem to get it up and running, I keep getting an error with pulling the ACME connection and the website wont go live at all. Think Im running into an issue with the domain name but Im not entirely sure. Is there anyone that might be able to help a lil bit?
Akov
2 Jul 2024 17:31
Call me crazy: If you deactivate a user....They cant login to seat, but if they are already logged in....they still have full access to any perms they had before. This is on v4, is that known/intended or just me?
Its unexpected behaviour at the very least
Raven
2 Jul 2024 18:37
The Deactivate User button calls the /account_status api which simply toggles the User's active flag and does nothing else.
I believe what you're hinting at is that this action should also deactivate that current web session. And you'd be right to think that.
Here's where that calls to and where you could implement that change -> https://github.com/eveseat/web/blob/5.0.x/src/Http/Controllers/Configuration/UserController.php#L152-L161
You could probably either call this in that code or add it to the auth middleware? I dunno what's best there. https://laravel.com/docs/10.x/authentication#logging-out
Akov
3 Jul 2024 02:53
I just cant believe there isn't an is active check some where
do you think here
https://github.com/eveseat/web/blob/5.0.x/src/Http/Middleware/Authenticate.php#L58
changing it to
php
if ($this->auth->guest() || !$this->auth->user()->is_active) {
not sure you can call user like that via auth
Raven
3 Jul 2024 18:50
I can't say right now if it's auth->user->isactive or auth->user()->isactive but ultimately that's good logic for middleware.
Maybe though on it's own if statement so it can log a specific response for that scenario if needed
Wibla
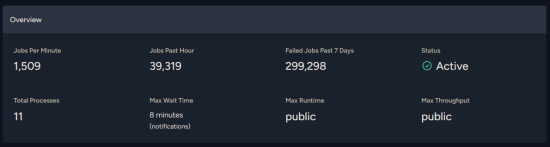
5 Jul 2024 20:02
I let that thing run ... but with 4GB redis and I guess you guys put the structure blacklisting stuff into redis? :v
recursive_tree
5 Jul 2024 20:04
The structure blacklist has always been in redis. But failed jobs also consume redis if I’m right.
Wibla
5 Jul 2024 20:04
yep
but that said I am not using a smart eviction setup for redis
I guess volatile-lru is better... if things are setup right 😄
Ncc-1709
6 Jul 2024 00:52
looks like you need to set your bucket update to 30 mins lol
Wibla
6 Jul 2024 16:40
also getting an enterprise-level drive to deal with the iops ...
found a dirt cheap used micron 5200 max 480GB drive that can do 4380 TBW
Ncc-1709
6 Jul 2024 23:02
see how setting the bucket helps
Matt Falahe
7 Jul 2024 03:26
Since the new equinox laravel is showing a long time for characters and notifications... is that normal? is there any way to check if thats real or fake?
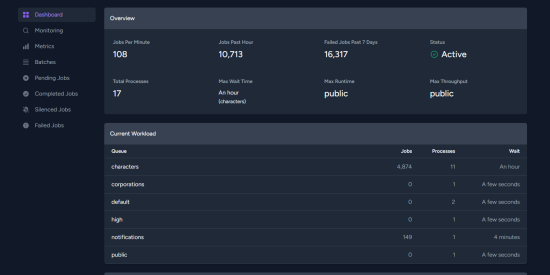
Wibla
7 Jul 2024 03:44
That's not going to charge things a lot
He11fire_[Vlad]
7 Jul 2024 12:24
Hi all! I want to remove from the seat people who, for one reason or another, left the corporation. I press the delete button, these characters are deleted. But after a few hours they appear again in this menu as if I had not deleted anything. What am I doing wrong?
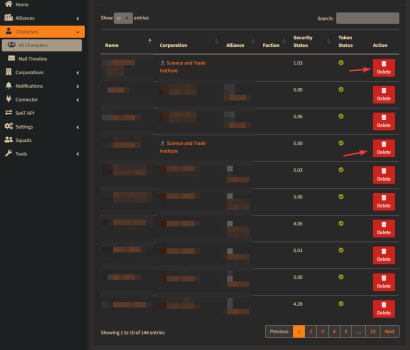
Tachi
7 Jul 2024 12:38
is backing up the bare version of seat5 this command?
mariadb db_name < backup-file.sql
Wibla
7 Jul 2024 12:40
mysqldump -uroot -p seat > backup.sql if you used the defaults during the install
Tachi
7 Jul 2024 12:41
so to back up a .gz file its zcat backup.sql.gz | mysqldump -uroot -p seat > backup.sql?
sorry i meant restore not back up XD
Wibla
7 Jul 2024 12:41
oh restore lmao
no
you're on the right track here
recursive_tree
7 Jul 2024 12:42
https://eveseat.github.io/docs/admin_guides/docker_admin/#database-backups-and-restore
just remove the docker parts
Tachi
7 Jul 2024 12:43
so just the same? mysql "$MYSQL_DATABASE" -u"$MYSQL_USER" -p"$MYSQL_PASSWORD"? and replace the $ variables?
yeah its working ty
recursive_tree
7 Jul 2024 12:46
you still need the zcat part:
zcat seat_backup.sql.gz | mysql "$MYSQL_DATABASE" -u"$MYSQL_USER" -p"$MYSQL_PASSWORD". and yes, you need to subsitute the env vars since it doesn't load the from the .env
Tachi
7 Jul 2024 12:55
yeah for some reason it wasn't working before, which is why I asked.
I might have used something else other than -uroot in the previous attempt and I also tried using gunzip rather than zcat like Wibla mentioned before this time to get it working. but its working now ty 😄
Ncc-1709
7 Jul 2024 16:32
it droped my error rate from 750k in 7 days to 10k.. so maybe it will
Wibla
7 Jul 2024 16:35
what was your previous schedule setting?
Ncc-1709
7 Jul 2024 16:35
it was default of 2 mins
Wibla
7 Jul 2024 16:36
so you changed it from 2 to 30 minutes?
Ncc-1709
7 Jul 2024 16:36
yeh, did try the steps in between but 30 removed most of the snowball issue
Kronosferatu
7 Jul 2024 18:21
I'm seeing that some components of my SeAT installation need updating, is there a guide somewhere on how to do this? sorry if it's a stupid q, I tried looking here https://eveseat.github.io/docs/upgrading/general/ ... is it really just running those 4 commands to update all the modules? or is that for when you're upgrading major versions (like say from SeAT 4.x to 5.x)?
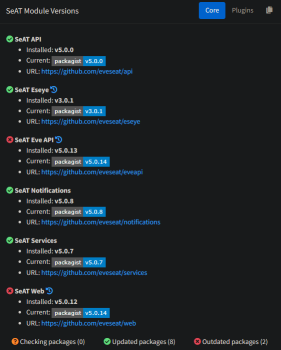
Matt Falahe
7 Jul 2024 18:36
https://eveseat.github.io/docs/upgrading/general/
Depends if you are docker or bare but yes that's all. You might want to do backup just in case before the update.
Kronosferatu
7 Jul 2024 18:37
I am docker. ok nice! seemed too easy so just wanted to ask here to be sure. thanks man!
and yeah I take snapshots before I do anything "big"
Wibla
7 Jul 2024 18:38
I set it to 24 minutes now for the lols, two updates per day for all tokens
Kwa Zulu
7 Jul 2024 19:21
Ugh
Matt Falahe
7 Jul 2024 20:20
I meant like an actual database backup...
Astral
8 Jul 2024 05:04
But wouldn't you want to keep the data..?
He11fire_[Vlad]
8 Jul 2024 10:18
Why do I need irrelevant data? It only take up space
Wibla
8 Jul 2024 10:47
historical data, and sometimes people revoke their tokens while still being in corp/alliance
hmm, this is new...
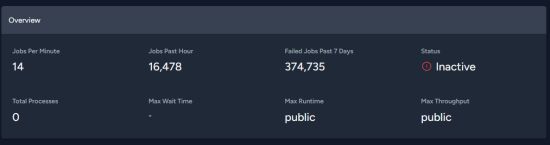
seems to have started this morning
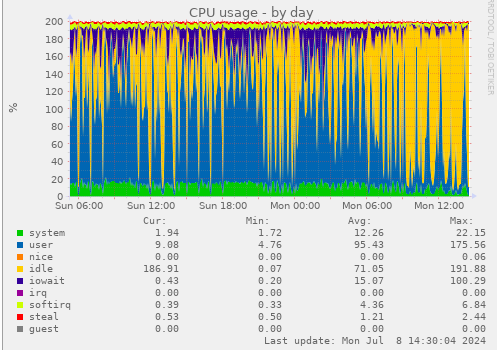
looks like redis
# keydb-cli info |grep memory_human
used_memory_human:7.45G
total_system_memory_human:15.62G
maxmemory_human:7.45G
# keydb-cli info keyspace
# Keyspace
db0:keys=652,expires=4,avg_ttl=23447,cached_keys=652
db1:keys=252142,expires=141,avg_ttl=369681604,cached_keys=252142
cleared cache, let's see how that behaves
are y'all not using TTL for redis entries?
So after 20ish hours of normal operation, redis stats look like this:
# keydb-cli info keyspace
# Keyspace
db0:keys=84563,expires=84395,avg_ttl=307580369,cached_keys=84563
db1:keys=244429,expires=13074,avg_ttl=5949813093,cached_keys=244429
recursive_tree
9 Jul 2024 08:08
Unfortunately, that doesn't really help. If you suspect TTL isn't set correctly, we'd need to know for which keys
I did just do an analysis of all keys without TTL on my dev install:
redis-cli -n 1 --scan | while read LINE ; do TTL=`redis-cli -n 1 ttl "$LINE"`; if [ $TTL -eq -1 ]; then echo "$LINE"; fi; done;
seat_database_seat:3.profile.email_address
seat_database_seat:3.profile.decimal_seperator
seat_database_seat:seat.recursivetree.allianceindustry.order.price.provider.default
seat_database_seat:2.profile.email_address
seat_database_seat:seat.bountytaxrate
seat_database_seat:3.profile.language
seat_database_seat:seat.ibountytaxmodifier
seat_database_seat:buckets:processed
seat_database_seat:1.profile.email_address
seat_database_seat:2.profile.language
seat_database_seat:1.profile.sidebar
seat_database_seat:seat.recursivetree.allianceindustry.deliveries.expired.remove
seat_database_seat:seat.cleanup_data
seat_database_seat:seat.recursivetree.billing.tax.generate.invoices
seat_database_seat:2.profile.skin
seat_database_seat:seat.installed_sde
seat_database_seat:seat.admin_contact
seat_database_seat:seat.registration
seat_database_seat:1.profile.language
seat_database_seat:seat.customlinks
seat_database_seat:2.profile.sidebar
seat_database_seat:seat.refinerate
seat_database_seat:seat.ioremodifier
seat_database_seat:seat.market_prices_region_id
seat_database_seat:seat.sso_scopes
seat_database_seat:3.profile.thousand_seperator
seat_database_seat:seat.analytics_id
seat_database_seat:seat.price_source
seat_database_seat:1.profile.thousand_seperator
seat_database_seat:seat.pricevalue
seat_database_seat:1.profile.skin
seat_database_seat:3.profile.skin
seat_database_seat:3.profile.sidebar
seat_database_seat:seat.irate
seat_database_seat:seat.ioretaxmodifier
seat_database_seat:seat.allow_tracking
seat_database_seat:seat.custom_signin_message
seat_database_seat:seat.allow_user_character_unlink
seat_database_seat:seat.oretaxrate
seat_database_seat:seat.oremodifier
seat_database_seat:1.profile.decimal_seperator
most are related to settings
please get one of these keys, what do they contain?
Also, are you sure you are in keyspace 1?
On another note, are you running with the redis eseye cache?
well that is a detail that matters
How much RAM do you allocate to redis? I think the esi cache can get quite big. If you put it in redis, you obviously need the RAM for it
The number of keys, 252142 divided by your number of tokens(4000?) gives you 63 keys per token. This is very much reasonable
I don't know how the TTL on the esi cache is set, but remember: The redis cache is kind of experimental. I suspect all testing has been done on dev instances
If you are running low on RAM, you might have to switch back to disk
And of course, we are happy if someone would contribute a fix
Personally, I really appreciate what you are doing. You are one of the biggest installs and we cannot test at that load, so I appreciate the feedback. However, being one of the biggest installs also means that maybe not everything runs as smooth
Wibla
9 Jul 2024 08:35
that sounds very interesting 🙂
are there any details you can share?
also re: disk cache, I had to prune that manually every few weeks too 😄
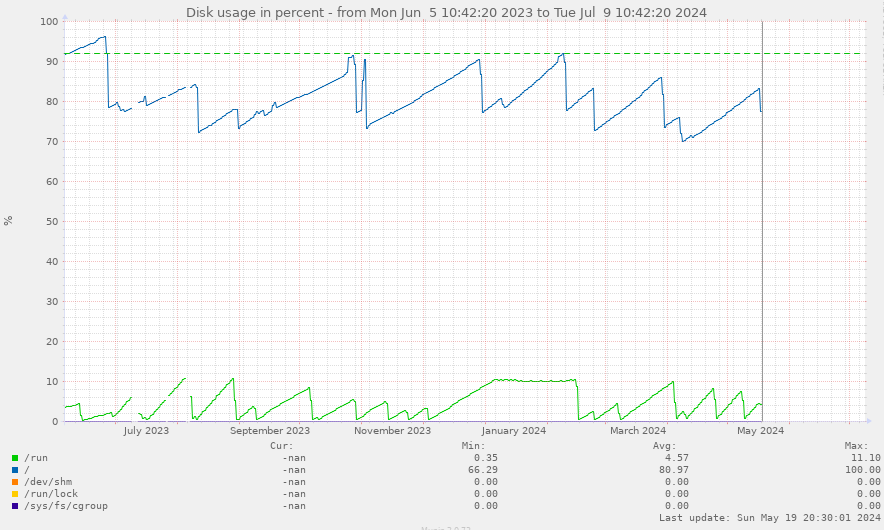
You can see where I moved to SeAT 5 here, and that's with eseye cache in redis:
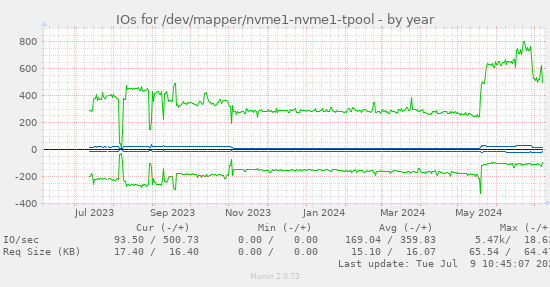
recursive_tree
9 Jul 2024 09:08
You can expect to use just as much redis RAM for the esi cache as it takes up space on your disk :)
Wibla
9 Jul 2024 09:09
well yes
but then we're back to the discussion of how long that data is supposed to live 🙂
Crypta Electrica
9 Jul 2024 09:12
On disk the cache entry will live until esi returns updated data, when an update is returned the old cache entry is deleted and the new is saved. At least that's how the code is intended to work
Wibla
9 Jul 2024 09:12
in practice there's a ton of stale data on disk
my extremely lazy approach to cleaning esi cache on disk has been to find all files older than 3 days and nuke them
recursive_tree
9 Jul 2024 09:18
on some endpoints, it is not unlikely that data doesn't change for 3 days. I'd say it can be argued whether it is really stale
Wibla
9 Jul 2024 09:18
that's true, but at that point it should be in the database?
recursive_tree
9 Jul 2024 09:18
esi might still return the same etag
Wibla
9 Jul 2024 09:19
it might, yes
but considering the already copious amount of bandwidth consumed, does it matter?
rx: 422.82 GiB tx: 226.98 GiB total: 649.79 GiB
monthly
rx | tx | total | avg. rate
------------------------+-------------+-------------+---------------
2024-06 246.04 GiB | 135.28 GiB | 381.32 GiB | 1.26 Mbit/s
2024-07 69.19 GiB | 38.01 GiB | 107.20 GiB | 1.26 Mbit/s
------------------------+-------------+-------------+---------------
estimated 253.17 GiB | 139.09 GiB | 392.26 GiB |
daily
rx | tx | total | avg. rate
------------------------+-------------+-------------+---------------
yesterday 6.92 GiB | 3.91 GiB | 10.83 GiB | 1.08 Mbit/s
today 3.37 GiB | 2.16 GiB | 5.53 GiB | 1.16 Mbit/s
------------------------+-------------+-------------+---------------
estimated 7.14 GiB | 4.57 GiB | 11.72 GiB |
recursive_tree
9 Jul 2024 09:20
The reason we use etags in the first place is to make ccp happy
Wibla
9 Jul 2024 09:21
that's fair
of course, CCP could have designed a less ||REDACTED|| API system and had less issues v0v
Crypta Electrica
9 Jul 2024 09:51
Is that docker bandwidth?
Because remember that if the etag matches, the body is populated from cache, instead of pulling it from ccp
Wibla
9 Jul 2024 09:53
this is a bare metal install
Crypta Electrica
9 Jul 2024 09:53
Ahh sorry true
Wibla
9 Jul 2024 09:53
so that's the VM network bandwidth
Crypta Electrica
9 Jul 2024 09:54
So I wonder how much worse it would be if we didn't use the cache.
Wibla
9 Jul 2024 09:54
good q
I nuked the cache Monday afternoon
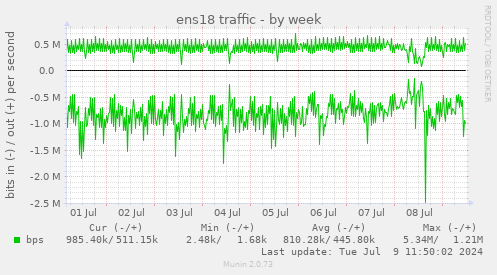
Crypta Electrica
9 Jul 2024 09:55
I have also been trying to see for your use case how to specify the null cache... But .env does not like null as an entry
Wibla
9 Jul 2024 09:55
😄
Crypta Electrica
9 Jul 2024 09:57
But I still am of the belief that the cache while not perfect is better present than not
Wibla
9 Jul 2024 09:57
I don't disagree
I just think that the TTL needs to be set to a sane value so redis can clean up as needed
(if using redis cache)
Calmingstorm
9 Jul 2024 20:58
Hope this is the right place to ask, I've recently installed seat - everything seems to be setup correctly. When running artisan seat:admin:diagnose everything is clear, I can see online player counts etc.
However, on my actual seat page - the characters I add never populate data, and I have this unknown error at the bottom. Laravel logs all seem clean, any ideas?

On the actual page, it's always just empty - including player count:
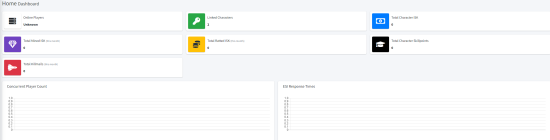
Using V5, manual install - let me know any other information I can add to help.
recursive_tree
9 Jul 2024 21:16
Does the error say anything when hovering over it? Also, are any jobs being processed?
Calmingstorm
9 Jul 2024 21:16
That's all I get when hovering over it, I'm unable to check if jobs are being processed - or rather don't know where to look to confirm. I've run some of the cron tasks manually, and it shows as if it's processed but nothing updates on the actual site.
When trying to view the system logs via log viewer in seat I actually get a 403, so have been reliant on checking /var/www/seat/storage/logs for logs.
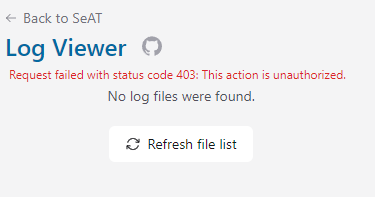
Restarting supervisor seems to have gotten some data to populate (online player count, for instance) and the red triangle/exclamation mark is now gone. Found where to check jobs, seems only Analytics is failing and the rest are in progress, should hopefully be in good shape now? I'll follow up if needed.
All good, that seems to have sorted everything out. The analytics failure is just a cert issue, no big deal. Thanks all.
jimsgonnasendit
9 Jul 2024 23:37
Hiya, does anyone have any experience moving to a new Redis store? I've come across the following when pointing to a new Redis host (ElastiCache in AWS):
CROSSSLOT Keys in request don't hash to the same slot
Context:
{
"exception": "[object] (RedisException(code: 0): CROSSSLOT Keys in request don't hash to the same slot at /var/www/seat/vendor/laravel/framework/src/Illuminate/Redis/Connections/Connection.php:116)
Utama
10 Jul 2024 02:22
Hey guys I got a question. Im new to SEAT admin and I was wondering if theres documentation of how ESI scopes are set up and assigned. I dont see anything on the official doc. Im wondering how I can set up for outside corp people can join seat without giving up everything including the soul of thier first born. I see theres different profiles in SSO tab but I cant find how to assign them. Thanks
Astral
10 Jul 2024 04:19
Just request the public scope on the profiles
public scope only includes data that any player looking at your character ingame can see
Which includes like your corp, The corp history and your ingame name
Fryke
10 Jul 2024 04:42
I'm having a very high number of failed jobs regarding character PI information. This isn't info that I feel like I need to track. Is there a way I can disable PI tracking temporarily until I get the time to do a deep dive on the errors?
Akov
30 Jul 2024 20:10
Drag the bot above the other roles on discord
Deags
30 Jul 2024 22:11
file: Discord_iLC7zgZ4TT.gif [not recorded]
And the role is below the bot position on the role list (like my Member role and such which work as intended)
Should I ping Warlorf about this in #channel_821361566184112181 ?
Akov
30 Jul 2024 22:22
Cool, there should be error in the log that tells you why
Deags
30 Jul 2024 22:27
I found out what happened
I had accidentally changed a vlue in the bot token, undid it, clicked save
didn't go through the whole process of reinviting the bot back to the server and it broke the connection between server/bot
redid that process, fixed itself
Akov
31 Jul 2024 02:46
nice
Glad I could be of no help
Utama
2 Aug 2024 23:22
Is there any way to get the seat discord connector to allow people to pick thier own nicknames?
More specifically I would like the option for seat to add the corp ticker, but then the user can pick whatever they want. Currently, the bot wil remove everything it didnt add itself, and if use ticker is unchecked, it just picks the connector name and wont let users change it. I know I can disallow the bot from changing nicknames at all, but is there an inbetween
Akov
2 Aug 2024 23:42
no
personally I had roles for every corp, and then use that + colors to denote folks corps
Utama
2 Aug 2024 23:43
Bummer, thas cool tho I like that idea
Akov
2 Aug 2024 23:43
but late made the culture decision that it was better if every one in discord saw each other as the same
so they still have individual corp roles, but you have to hover to see that or what ever
Utama
2 Aug 2024 23:43
So i guess just kick the bot and then reinvite without nickname permissions
Astral
2 Aug 2024 23:45
Just remove the bot permission over reinviting..?
Akov
2 Aug 2024 23:45
pretty sure you will fill your logs with errors
fair warning
Utama
3 Aug 2024 00:17
Seems you can’t remove that permission
Astral
3 Aug 2024 00:21
Yeah probably would but there's no real point in removing the entire bot to just take a perm away to test
Akov
3 Aug 2024 03:41
no either way it will spam the logs
disi
3 Aug 2024 19:34
Hmm what could be the reason for corps not show at all corps? I do not see anything in the error logs at all, just not showing in the view
Akov
3 Aug 2024 19:53
as in, it doesnt show a corp that you have keys for?
disi
3 Aug 2024 20:23
hmm more as in it seems the corps are not updated via esi
Akov
3 Aug 2024 20:56
corp names are, but searching for them only shows up if you have a key